栏目索引
相关内容
京东618期间,各种促销活动,用户下单量激增,促销活动所产生的价格波动频繁,为了保障用户权益,拒绝站在价格的高岗上,京东推出了特色服务——价格保护。当促销活动正式开始时,不少用户开启了价格保护,在此高并发情况下,如何保证用户体验,如何保证系统的稳定性、高可用、快速计算结果,是本文的重点。
我们将按照下图进行实践分享:

一、高筑墙
对于任何网站,我们的系统都需要做出防护措施,面对海量流量,保障系统不被冲垮;需要通过一些像限流、降级等技术,对系统进行全方位保护。
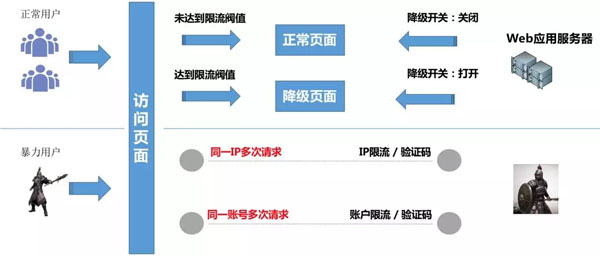
从上图可以看到,我们针对正常用户和暴力用户在不影响用户体验的前提下,采取降级、限流等措施,以保障系统稳定。那么我们是如何做的呢,下面我们分别来说说限流、降级。
1. 限流
(1) 正常用户限流
正常用户访问时,超出了系统的承载能力,这时就需要做限流,防止系统被打垮导致不可用。
通过压测,得到单台机器的最大承载能力,而后在单台服务器上通过限流计数方式进行访问次数统计,设置在一段时间内只可访问N次。例如,设置1w/分钟,当在1分钟内达到阈值时,将进入降级配置,过了该时间段后,在第2分钟时,又重新进行计数,以此保证单台机器不会超出最大承载能力,后续每台服务器都按照这个阈值进行配置。
(2)暴力用户限流
暴力用户频繁刷应用系统,我们需要在这层做一些防刷,比如清洗恶意流量、做一些黑名单。当有恶意流量时,通过对IP、用户等限制手段把它拒绝在系统之外,防止这些恶意流量把系统冲垮。
这里通过redis计数,按照IP或用户的维度,进行原子加1,限制120/分钟,防止恶意流量影响到我们的正常用户访问量。
2. 降级
当某个接口出现问题时,我们能够对该接口降级,快速将结果返回,不影响主流程。
那么降级是怎么做的呢?

由于我们分布式集群,应用服务器数量很多,因此,我们需要将降级开关集中化管理。这里我们制作了统一的配置开关组件,通过zookeeper将配置推送到各个服务器节点,同时在zookeeper及应用服务器上分别会有快照数据,保证如果统一配置开关组件发生问题,我们应用也会读取本地快照数据,不影响应用本身。同时在应用重启的时候,我们也会通过接口拉取配置中心上的最新快照。
对于降级,我们也需要友好提示,在前端如果降级,我们需要友好提示,或者展示降级页面,尽量不影响用户体验。
二、广积粮
对于大并发网站,我们需要进行各种数据准备,需要区分动态资源与静态资源,将静态资源进行缓存,以应对瞬时访问量。

1. CDN
页面上的静态资源,如js、css、picture、静态html等资源,可以提前准备,放到CDN,当页面请求时,可将这部分网络请求打到CDN网络上,减少连接请求,降低应用服务器压力。
采用CDN时,我们需要注意,当web页面与js发生改变,无论是先部署web应用,还是先推送js到CDN,都有可能发生js脚本错误。因此,我们需要在web页面上做CDN切换开关,先将资源访问切换到web机器上,待上线验证后没有问题,再部署CDN,切换静态资源访问到CDN。
2. 数据缓存
我们在获取数据时,应先做出判断,哪些地方可以用缓存,哪些地方需要读数据库。动态资源固定属性,高频访问,则应主动缓存。例如,订单下单时快照,订单的类型、下单时间、订单内商品、商品下单价等,就是固定不变的,我们通过接收订单下单消息,进行数据主动缓存,以便后续展示订单内商品价格、计算价保申请时下单价及促销价做出准备,而无需实时访问订单接口,降低了后端接口压力,也加快了获取速度。
三、化繁从简
在高并发情况下,需要快速响应,当请求过程中,获取过多的数据,则有可能会降低响应速度,因此要将处理简单化,只做黄金流程即可。
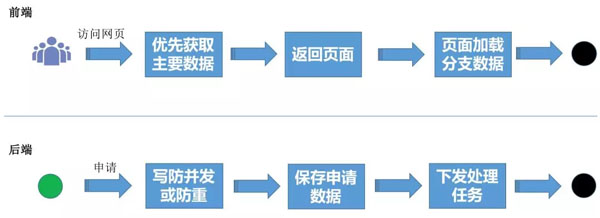
1. 前端从简
#p#分页标题#e#用户访问页面时,只关心关键部分数据,因此我们需要优先获取主要数据,立刻返回页面,由页面通过ajax加载分支数据,达到页面完整性。这样既保证了用户体验,又提升系统的响应能力。
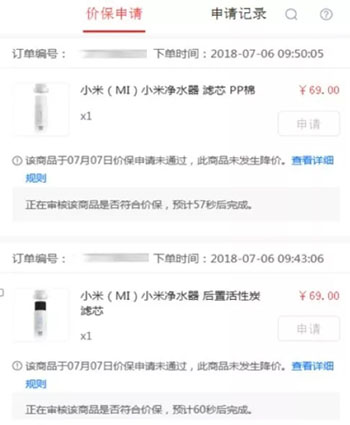
图-价保申请
以价保申请页面为例,用户进入页面,就是要进行商品价格保护,因此商品列表、申请按钮,是用户最想看见的。其他的信息,如商品最近一次价保记录、下单价格等数据,就可以后续再进行加载。
2. 后端从简
用户进行价格保护申请时,由于处理逻辑非常复杂,需要和20多个系统进行交互,才能计算出结果,因此我们采用异步处理方案。那么在接入申请时,任何系统都可以用三步方式接入申请:
插入防重
保存申请数据
下发处理任务
这样保证了用户申请可快速接入,提升系统的接单能力,后续对处理任务进行加速,则可以很快的返回结果,不影响用户体验。后面的章节“处理无极限、速战速决”会具体讲解如何最快的处理任务。
四、合二为一
在高并发请求下,由于请求数巨大,cpu会频繁切换上下文,导致cpu使用率飘升、性能下降,因此我们要尽量减少请求数,将可以合并的进行合并。
还以上面“图-价保申请”为例,由于订单内商品价格在后端已经缓存,我们可以将商品价格按照订单的维度进行合并,同一个订单下所有商品价格通过一个ajax进行请求访问。刷新是否符合价保请求进行合并,无论用户点击了多少次申请,都以一个ajax进行组合刷新结果,这样就减少了请求后端的连接访问。
五、分而治之
1. 前端网站
我们按照访问来源、主次流程进行集群分散:
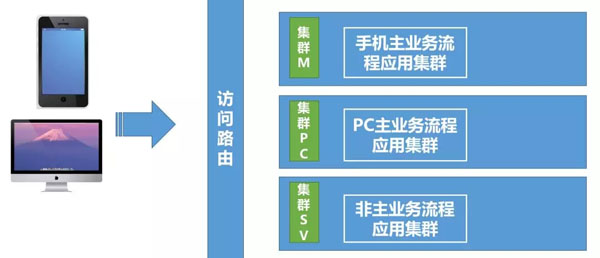
目前很多网站都制作了手机端、PC电脑端,因此按照访问来源,我们应用集群也进行区分。这样做不但可以使各个来源集群相互不影响,还能根据访问来源不同的访问量,合理分配机器。
同时,我们还按照了主、次业务,进行了集群区分,将不重要的业务放到非主业务集群上,使其不会影响到主业务流程。例如“图-价保申请”中所示,价格、最近一次访问记录、申请结果刷新,这3个功能就不是主业务流程,将它们放在非主业务集群上进行访问,就算非主业务集群出现问题,也不会影响到价保黄金流程。
2. 后端数据
后端进行读写分离,分库分表:
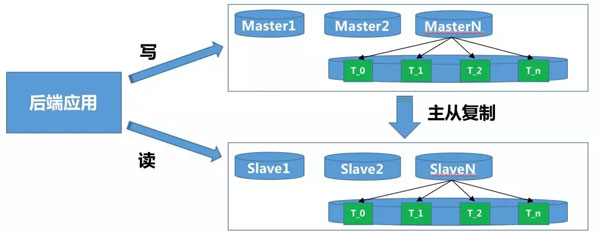
对数据查询时,是否需要实时数据,决定是否采用读从库。
对大量数据写时,应将数据按照业务需要的维度进行分库分表,降低数据库压力。
这里我们说下我们是如何进行分库的。价保系统的主要维度是用户,因此我们按照用户PIN进行分库路由,以用PIN取Hash值,然后取模。例如我们要分2个库,则算法hash值%2。那么问题来了,当业务量开始增长,2个库满足不了我们的要求,需要扩展更多的库,例如5个库,怎么办?一般做法是将2个库的数据进行清理,然后按照新的库个数5重新打散数据,hash值%5。
这样做实在太麻烦了,因此我们这里采用二叉树算法,可以很平滑的扩容数据库,不用进行数据打散重新分配,怎么做的呢?下面我们先回忆下二叉树:
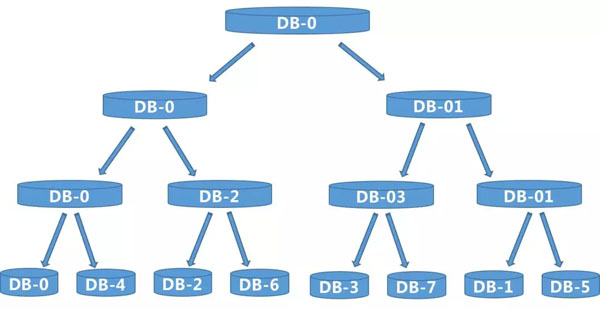
从上图可看出,1个→2个→4个→8个,新裂变出的节点,只需要将数据冗余父节点,按照2的N次方,向下裂变即可。
那我们看看是如何进行扩容的:
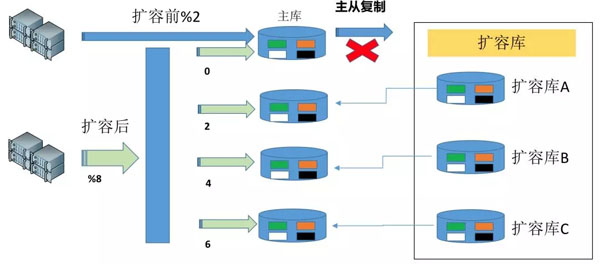
在扩容前,有2个数据库DB-0和DB-1,现在需要扩容到8个数据库,以DB-0为例:
我们只需要新找3台数据库,挂载到DB-0上当做从库,而后进行主从复制;
在数据量最少的时间段,将主从复制切断,同时将扩容的ABC三个从库切换为主库,此时4个数据库数据一致,每个有1/4的数据属于自己,其他数据则为冗余数据。
#p#分页标题#e#将路由算法调整到 hash值%8,部署新应用,将所有主库连接上后进行接量,此时有新、旧2个应用同时在。但是如果旧应用接量,则同步不到新裂变出的数据库2、4、6上;
制作数据迁移任务、数据比对任务,将0库按照切断主从复制的时间开始,按照hash值%8,将2、4、6的数据(以最终状态为准)同步到各自的库上,同时做数据比对验证;
停止旧应用,由扩容后的新应用开始承接所有的量,此时,数据库扩容完成。
在扩容完成后,我们只需要做冗余数据的清理即可,实现方式很多,例如可以通过数据归档任务:
写防重
一定时间段之前的数据进行归档
这样,经过一段时间后,冗余数据就会被清理掉,同时因为有防重,也不会出现多次归档导致归档数据重复。
六、处理无极限
经过上面的几步,用户可正常的打开页面,提交商品价格保护申请,那么如何能将这巨大的申请量全部吃下,并迅速的返回,成了我们系统的一大难题。处理的慢,就有可能获取当时促销价不准确,导致用户价保失败,用户体验会急剧下降。
下面我们将演示如何从有极限到无极限:
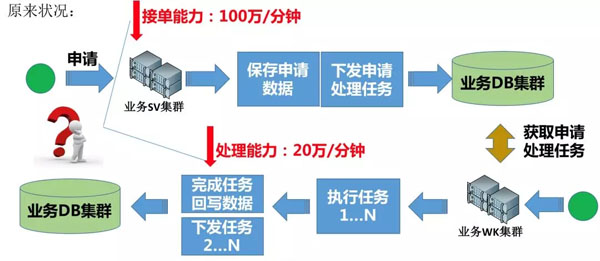
图 – 有极限
大家看,为什么上图是有极限呢?
从申请入库到处理申请任务,都是采用业务DB集群,这样的话,如果接单能力100万/分钟,处理能力只有20万/分钟,此时数据库已达到瓶颈,那么想要处理的更快,只能继续做分库,添加业务WK集群机器,这样也能让处理能力上升,但是接单能力这边就会出现极大的浪费。
通过这些,想必大家也能猜到,对,我们将接单、任务处理2个集群的DB分开,就能解决这个问题,同时相互间也不会有任何影响。怎么做呢?请看下图:
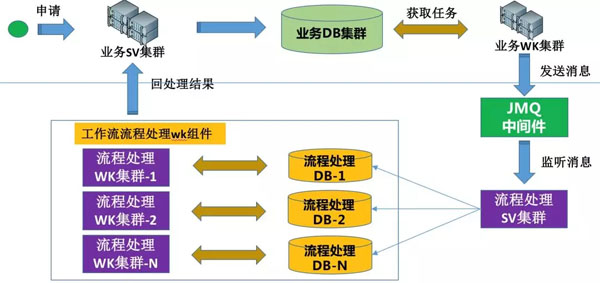
我们业务接单集群,只做业务处理,保存到业务DB集群,通过业务WK集群,将任务下发到JMQ中间件,任务流程处理SV集群进行消息监听,将消息分库插入到流程处理DB中,每个流程处理DB都会对应一套任务处理WK集群,那么按照上面20万/分钟来算,我们这边只需要5套即可。这样无论业务申请如何大,我们任务处理都可以随时扩展。
七、速战速决
在上述“处理无极限”中,我们已经可以随时扩展,那么怎么才能最快的任务处理呢?这节我们主要说说怎么让任务处理速度最快,同时在出异常的情况下,任务不丢失。
由于价保申请处理,业务非常复杂,我们这里采用工作流模式,以任务节点程序全自动进行处理。我们来看下,任务系统是如何演变,最后达到速战速决的。
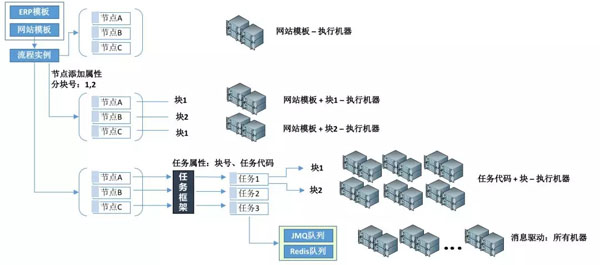
工作流的流程介绍:通过工作流流程模板Template,一个申请Apply生成一个流程实例Order,每个流程实例Order下会有N个节点任务Task。
第一阶段
按照Template维度,定时获取一定数量的Task,循环执行。以机器充分执行任务的角度来看,此时一台机器即可,两台机器执行,则有可能抓取到相同的任务,导致资源浪费。
第二阶段
数据分块:将一批数据,按照预先设定好的进行分块,而后可对分块数据进行区分对待。
如上图,对任务节点Task进行分块,此时定时获取Task 维度发生变化,可从Template、块2个维度获取Task,目前分为2个块,则该模板可执行机器为两台;块号越多,则该模板执行的机器越多。
但是我们发现,最小粒度是Task,为什么要有Template的维度呢?
第三阶段
将Template维度去掉,采用Task最小粒度维度,上图中使用了任务框架,是我们自主研发的,如不使用该框架,只要保证最小粒度为Task,一样可行。
我们将Task以Template+TaskCode生成任务代码,再在Task上面进行分块,则达到了最小粒度:任务代码+块。如上图所示,还是每个任务分2个块,此时3个任务2个块,一共可以有6台服务器进行任务执行。此时速度已经很快了,按照最小粒度进行区分,但是还是有机器的数量限制,只能加大块号,以便更多机器可以执行。
第四阶段
在生成Task节点的同时,将该节点信息下发到消息队列,通过消息进行驱动,从而达到所有机器接可执行,将速度提升到最快,此时只要保证任务内部处理够快即可。
在此阶段,当任务执行异常、消息丢失,我们还有第三阶段的方案进行保底、重试,同样保证任务可高效执行。
#p#分页标题#e#夏庆峰:逆向流程技术专家,疑难杂症的终结者,2014年加入京东,负责京东财务退款及价格保护研发建设,擅长京东逆向流程场景、金额拆分计算、高并发下网站优化。
【本文来自51CTO专栏作者张开涛的微信公众号(开涛的博客),公众号id: kaitao-1234567】
戳这里,看该作者更多好文