文/木遥(微信公众号:木遥)
一家名叫 SourceFed 的独立媒体的一则报告在中美互联网上都炸锅了。
它的中心思想是:通过搜索一系列关于希拉里的负面新闻,发现谷歌的自动提示竟然没有包括一些明明应该被广为搜索的词汇组合,比方说,当你搜索 hillary clinton criminal 这个攻击希拉里的常见词汇组合的时候,看到的不是 crime reform,就是 crisis,总之是一些比较中性的词汇。通过 google trend 这类反映网民搜索趋势的工具很容易查到,搜索希拉里 criminal 的人明明远比 crime reform 为多,所以这充分说明,谷歌在作弊。
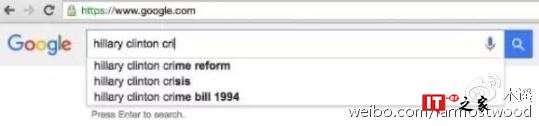
结论是:谷歌在操纵舆论,偏向希拉里。你可以在这里看到比较完整的指控:
现实版《纸牌屋》?谷歌被指屏蔽对希拉里不利信息
这个结论收到普遍欢迎并不奇怪。很多人不喜欢希拉里,或者不喜欢谷歌,或者对它们并无成见,只是喜欢阴谋论。但也有很多人,觉得自己一贯持平公允,看了这篇文章也不禁开始怀疑。文章看起来有理有据,总得有个解释吧?
其实解释起来再容易不过了。首先,大多数网民搜索希拉里的时候根本就不会打全名,特别是要搜索负面信息的网民。如果你只搜索 hillary,你其实是能看到 criminal 这类负面讯息的:
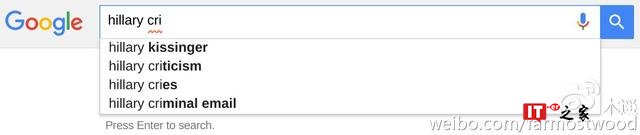
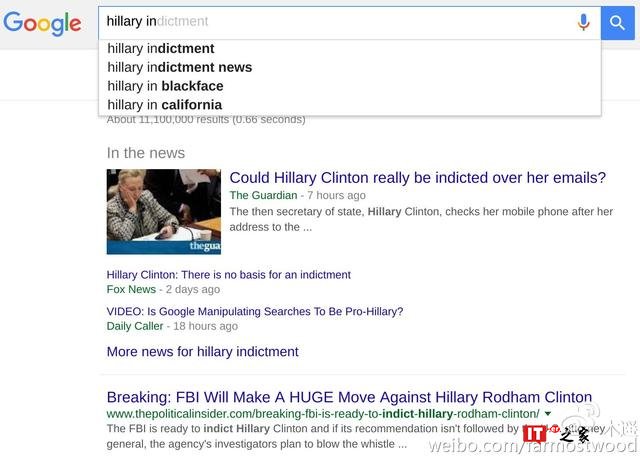
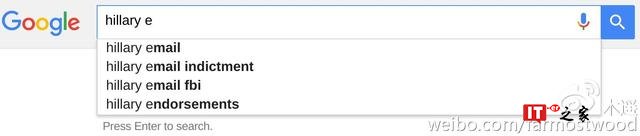
那么为什么在搜索 Hillary Clinton 全名的时候没有这些结果呢?因为谷歌的政策是尽量不在全名后提示负面词汇,以免自动提示这个功能被利用成为在网络上攻击他人名誉的工具。这个政策是对所有人一视同仁的。比如川普,尽人皆知,川普的一个著名丑闻是涉嫌强奸自己的前妻。Donald Trump rape 或者 Donald Trump lawsuit 和 Hillary Clinton Criminal 一样都是网民搜索的热词。但是在谷歌的自动提示里,也不会出现这个组合:
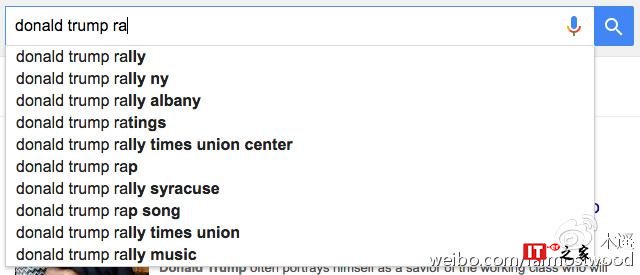
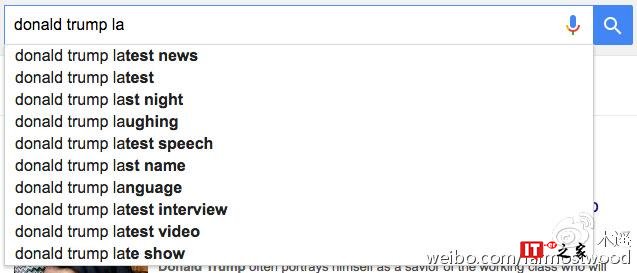
抓到了!原来谷歌在同时讨好希拉里和川普,两面押宝,真是用心险恶啊……
其实,即使没有所有这些实验,要看出原文的问题也不困难,这里实在是有太多逻辑上的漏洞了:
一、原文所依赖的基本假设是:谷歌的自动提示应当完全依赖于网民的搜索热度。只要两者有偏差,就说明谷歌在作弊。可是这假设并不成立,即使不熟悉技术的人,只要有基本的直觉就会懂得,自动提示这类功能在设计的时候当然不可能只考虑一个影响因素。这道理很简单,稍加思索就会明白。
二、即使原文的基本假设成立,观察到「希拉里的搜索结果有差异」也不能说明谷歌偏向希拉里,至少得说明「只有希拉里的搜索结果有差异」才行。原文甚至连这个基本功课都没有做。
三、再假设,即使真的观察到了只有希拉里的搜索结果有差异,是不是就能说明谷歌偏向希拉里?还是不行,任何智能算法都会有出错的基本误差,需要证明,希拉里的误差是如此之大,以至于一定不可能是随机因素造成的。这就需要至少做一点基本的数据统计和搜集,有多少常见的负面词汇,这些负面词汇应当以什么频率出现,实际上的频率是怎样的,偏差的置信度是多少,诸如此类。只靠 criminal 或者 indictment 这一两个孤证来作出结论,这在任何正式的研究项目里都是要被笑掉大牙的。这和说一个人某天出门路上比平时多花了十分钟,所以一定是去从事不法勾当了,没什么本质区别。
一家独大的搜索引擎对社会公平的影响不是什么新鲜话题。归根结底,人们依赖谷歌至深,而谷歌的算法又全然隐藏在黑箱之内。所以下面这个问题看起来既合情,也合理:我们难道没有权利要求一家搜索引擎给我们一个「真实」的舆论场吗?
没有。因为世界上并不存在这样一个天上掉下来的真实。
在搜索引擎出现之前,人们获取信息的渠道是广播、电视、报纸、小道消息……它们没有一样是不能被特定的人和权力所把持和影响的。事实上,在人类历史上的大多数时期和大多数文化里,操控舆论甚至都未必是一个负面词汇。舆论从来就是被人控制的。
#p#分页标题#e#
搜索引擎在人类历史上第一次让算法替代人来进行信息的分拣和排序——搜索和过滤本来就是同一件事的两种不同的称呼。随着算法越来越复杂,人工智能所占据的重要性越来越高,我们正在一步一步地让信息流通摆脱人为因素的作用。
但我们并不能指望算法最终还原给我们一个客观的真理世界。真理不该是这样获得的。获得真理的根本途径,是自己的思考和怀疑,聆听和理解不同的声音;是摈弃简单粗暴的结论,理解和欣赏世界的复杂和多样性;是掌握基本的统计学知识,了解如何看待数据的规律,懂得人类在原始时代进化出的本能直觉很可能并不一定适应当代社会;以及最根本的,是不要让立场控制自己的思想。这不是算法的责任,这是你的责任。
如果你做不到这些,你当然会被操纵,但别让谷歌背这个锅了,这是你自己选的。