栏目索引
相关内容
背景
随着神盾推荐业务场景的不断深入,传统的离线训练+线上计算的模式可以说是推荐系统1代框架,已经不能完全满足部分业务场景的需求,如短视频、文本等快消费场景。下面先简单介绍下传统模式以及其在不断变化的场景需求中的不足点。
传统模式简单介绍
传统模式下,整个推荐流程粗略可分为,数据上报、样本及特征构造,离线训练评测,线上实时计算,abtest等。
• 优点:
系统架构简单
普适性较强,能满足大多数业务场景。
• 缺点:
数据及时性不够。
模型实时性不强。
下面举一个简单例子,来说明这样的问题:

小明同学在微视上看了一个视频,那么在推荐场景下,可能会遇到以上四类需求,并且每种需求对于数据的实时性要求并不一样。从推荐系统功能来看,可以概括为已阅实时过滤、用户行为实时反馈、物品池子更新等。所以如果要满足业务需求,从代码层面来看,这样的需求并不复杂,但是从架构层面或者可扩展性来说,神盾作为一个面向不同业务的通用推荐平台,就需要提供一个能满足大多数业务,对于快速据消费的通用平台。
针对不同业务、不同场景需求,神盾希望构建一个快数据处理系统,旨在满足更多业务场景的快速据消费场景。
任何系统的搭建及开发离不开特定的业务场景需求调查,神盾根据多年业务经验,收集归纳了相关快数据处理的相关需求,具体如下:

我们深入调研、讨论,结合业界实践以及神盾的实际情况,总结为两类系统需求:
• 1、 近线系统。满足业务对于物品、特征、及其他数据类服务的准实时更新。
• 2、 在线学习。满足业务对于模型的准实时迭代更新。
基于以上调研,神盾推出Quicksilver(快数据计算)系统,解决推荐场景下快数据计算及更新问题。
系统设计Quicksilver系统是一个集近线及在线学习能力为一体的通用架构系统,我们设计之初,从收、算、存、用四个维度来进行设计,如下:
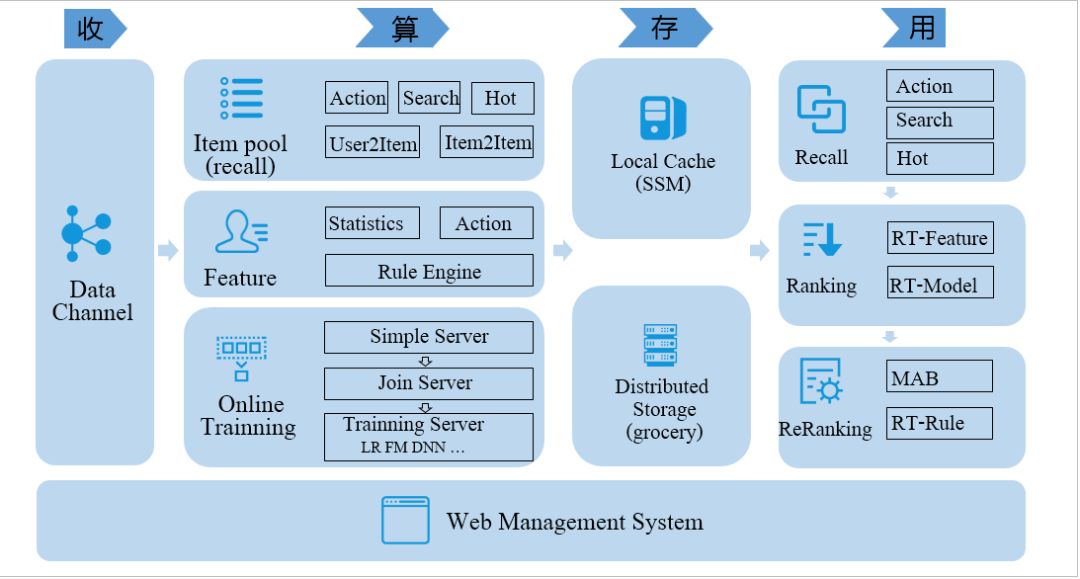
• 收:数据的收集。目前主要支持基于DC、TDBank数据通道上报。
• 算:计算层。针对不同的数据类型,定义不同的计算模块。不同的计算模块,采样不同的技术方案来实现。例如对于物品池子此类分钟级更新要求的数据,我们采用sparkstreaming,而对于用户行为实时反馈等类数据,我们采用spp实时处理类服务器框架。设计中屏蔽掉用户对于底层实现的细节。
• 存:存储层。针对不同的数据规模及访问频率,神盾采用不同的存储介质来满足数据存储的要求及对线上服务延迟的要求。例如对于物品类特征、池子类数据,神盾采用自研的SSM系统,而对于用户类特征,数据量较大、存储访问实时性要求也较高,我们选型为公司的grocery存储组件。
• 用:使用对接层。通过Quicksilver计算得到的数据,我们均通过神盾产品化来配置管理,降低对于数据使用的门槛,最终可以通过配置,直接与线上的召回、精排、重排、规则等计算单元进行打通使用。
架构实现
以上为Quicksilver整体架构实现图,主要分为近线系统及在线学习系统。下面详细介绍。
近线系统
近线系统主要为了满足以下几类细分需求:
• 实时召回:
Quicksilver处理物料,经过各通道后到线上 (要求秒级,实际分钟级)
• 实时因子:
Quicksilver统计计算,经过各通道后到线上(分钟级)
• 实时特征:
统计型(物料、行为、场景):Quicksilver计算,经过各通道后到线上(分钟级)
实时特征(用户):实时特征构造引擎构造,构造后直接对接线上(秒级)
于是,在选型上,我们针对不同的数据计算模式,选择不同的计算平台,对于统计类型数据,我们选择sparkstreaming来作为我们的计算平台,对于实时性要求较高的数据,如实时反馈类,我们采用spp来进行平台型封装。
数据批处理
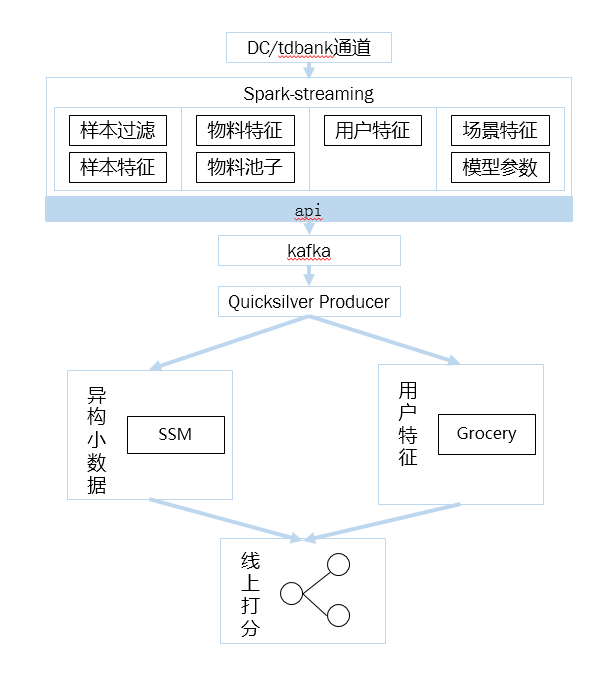
数据批处理是基于sparkstreaming实现,如上,有几点说明:
1、对于使用者来说,采用api接口封装,下层通信等均透明化处理。用户只需在处理不同的数据时,选择不同的接口即可,如物品池子接口,特征接口等。使用PB协议进行下层数据通信。
2、底层数据生成后,使用kafka进行缓存。
3、数据线上使用时,统一在神盾产品化上进行配置管理,降低运维成本。
数据实时处理
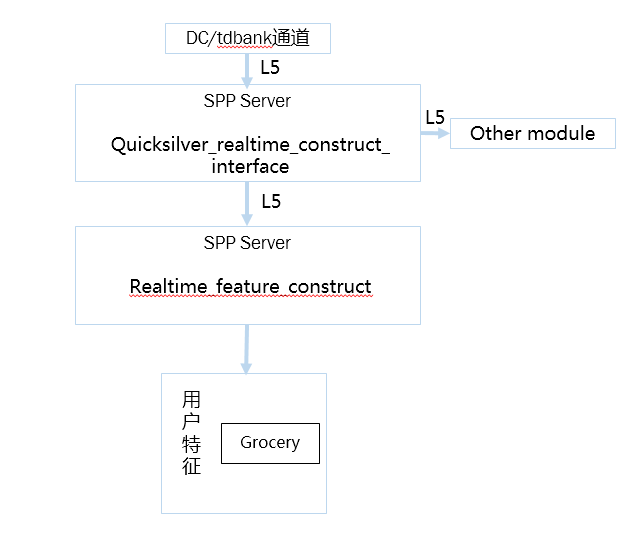
数据实时处理是基于spp server实现,如上,有几点说明:
1、对于用户来说,希望一次转发,多次使用。Quicksilver通过接入层interface来实现,业务只需要转发到统一的对外L5,即可实现数据一次转发,多次使用,如部分业务可能想即进行特征构造,有可以将数据转发到样本构造,在此即可实现。而所有的这些配置,也通过神盾产品化进行配置管理。
2、对于不同的业务,由于数据上报标准不一样,那么如何实现不同的数据上报标准都可以在Quicksilver上使用,这是实际中遇到的挺头疼的一件事。我们将这样的问题拆解成不同的数据标准,转化成神盾统一的上报标准的问题。于是,在实际代码开发中,只需要留出这样的转化接口,不同的业务实现不同的接口,并可以根据配置选择不同的接口,那么即可解决这一的问题,在这里,反射即可以很好解决这一的问题。
在线学习
在线学习有两方面优点,一是充分利用数据时效性,实时跟踪用户对物品的偏好,比如10点钟上线的新游,在11点的推荐结果中就可以反馈出不同用户对新游偏好情况,使得在尽快适应用户偏好同时,提升了apps转化率;二是在线学习前提是标记数据和特征在线拼接,该操作可以在一定程度上缓解模型离线训练资源不足瓶颈。
以某apps推荐为例,面临效果提升瓶颈,我们分析有两方面原因导致,一是数据源红利降低(新增数据源成本越来越高);二是高维线性模型遭遇瓶颈,暴力式特征交叉是LR模型提升特征维数的主要手段,它存在两个问题,一方面,做不同特征之间交叉组合需要一定成本,另一方面,无法穷尽所有交叉组合方式。
面对推荐效果提升瓶颈问题,有三种解决方案,一是继续想办法引入新数据源构建特征;二是充分利用现有数据源,尝试更好特征工程方法,比如Stacking集成或者特征工程自动化;三是考虑充分利用数据时效性,引入在线学习方案,实时跟踪用户对apps偏好变化。
Quicksilver在线学习架构设计如下:
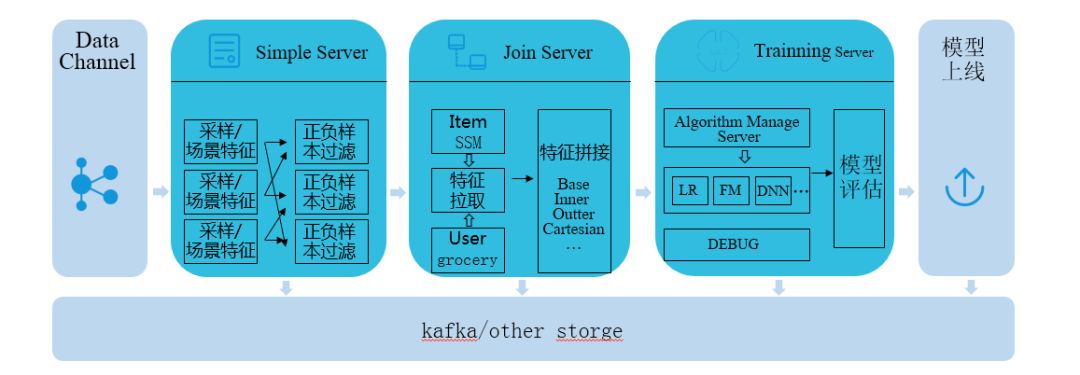
整个系统主要细分为5个小模块:
• 样本采样:根据模型的优化目标支持自定义采样方法,同时在后期也需要将场景特征考虑进来,采样的结果作为实时拼接的输入
• 实时拼接:将实时样本的userid 、itemid的全量特征进行拼接,拼接的结果一方面可以作为离线平台的输入,另外一方面也可以作为特征引擎的输入;
• 特征工程引擎:根据各个在线训练算法的特征配置,从拼接好特征的样本中进行特征选择、特征交叉等操作,并将处理的结果写入kafka消息队列,模型训练和模型评估模块消费消息队列里面的数据进行训练和评估;
• 流式训练:消费kafka里面的样本数据,采用onepass或者minibatch的形式进行模型参数更新;
• 模型评估:对模型训练出来的模型实例,从kafka消费实时样本数据对模型进行auc评估。
下面关于几个较重要模块进行较详细介绍:
样本采样

• 使用spp server实现类map、reduce操作,采样的结果支持存储到kafka或者下一个实时拼接模块。
• 采样规则引擎基于flex/yacc设计实现。
• 所有采样的配置信息,均通过神盾产品化实现管理。
特征拼接
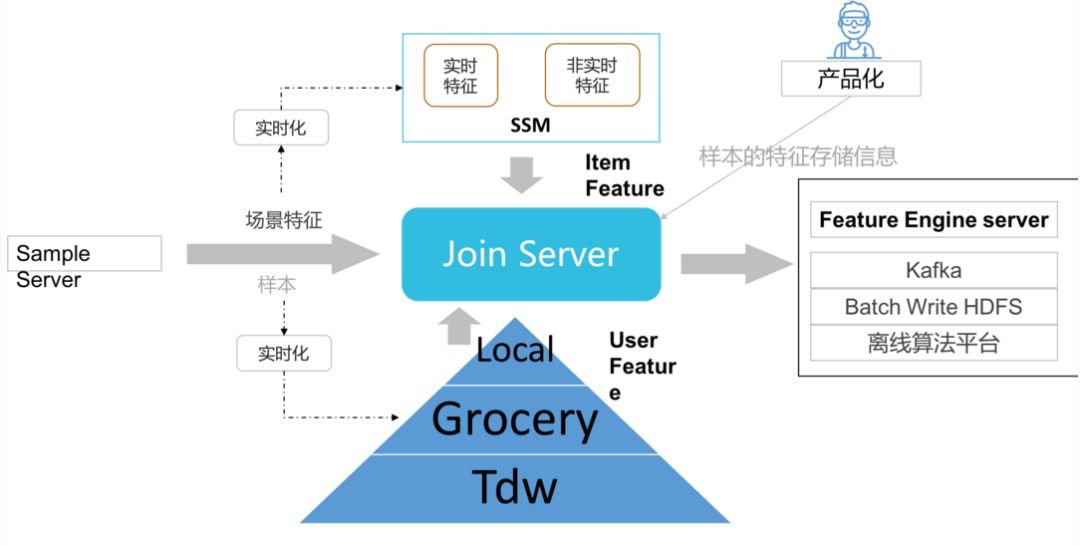
实时拼接服务主要是将样本中包含的物品和用户的“全量”基础特征拼接到一起,为下一步实时特征提供原料。 特征来源有是三个不同的地方:
• 用户特征(包括实时用户特征):目前主要是来自grocery
• 物品特征(包括实时物品特征): 目前主要从SSM中读取
• 场景特征:是在采样的过程中生成。
实时特征拼接后,下一步便是特征工程引擎的环节,目前主要支持内积、外积、笛卡尔积三种模式,在此不详细介绍。
模型训练

• 目前主要实现基于FTRL的lr及fm算法实现,正在调研参数服务器大规模生产环境使用的路上。
#p#分页标题#e#• 动态采样:有的算法算法需要控制正负样本的比例,但线上的流式训练与离线的batch不同,不能再训练之前就知道本次训练总样本量是多少,以及正负样本的比例,故需要根据设置的正负样本比例值,根据时间的推移来动态控制,即在训练的过程中动态采样。
• 低特征覆盖:为了提高模型的可靠性,其中方法之一就是在模型中结合场景特征屏蔽掉低覆盖度特征,与动态采样一样,流式训练时,在训练前无法统计提前统计出每个出现的频率,故也需要动态过滤低频特征,此方法不仅可以用在模型启动时,对于新加入的特征同样适用
模型训练后,即效果评估及上线环节,目前主要支持AUC、MAE等主要评估指标,在此不再详细赘述。
写在最后对于任何系统设计来说,都不应该脱离实际的应用场景,这是神盾推荐系统一直贯彻的原则。Quicksilver系统也是神盾这么长时间来从实际的业务场景中收集需求、设计、实现的,已经在空间、电竞、手游、动漫、京东等多个业务场景中上线使用,并取得了不错的效果。神盾也不断在实际场景中继续完善、优化其中的相关能力,给业务带来更高的效果提升。
来源:腾讯QQ大数据
更多阅读:
腾讯QQ大数据:相关推荐之反浩克装甲
腾讯QQ大数据:从用户行为去理解内容-item2vec及其应用
腾讯QQ大数据:机器学习建模问题中的特征构造方法
腾讯QQ大数据:逻辑回归如何用于新用户识别与触达
腾讯QQ大数据:聚类算法如何应用在营收业务中——个性化催费的尝试
腾讯QQ大数据:神盾推荐——MAB算法应用总结
腾讯QQ大数据 :从“增长黑客”谈数据驱动的方法
腾讯QQ大数据:一种海量社交短文本的热点话题发现方法
腾讯QQ大数据:视频打标签算法探讨
腾讯QQ大数据:用户增长分析——用户分群分析
腾讯QQ大数据:BI方法论-数据体系建设之路
腾讯QQ大数据:产品指标体系如何搭建
顶尖调查记者的数据处理与可视化利器推荐
什么是数据处理?