栏目索引
相关内容
由于机器学习可能涉及到训练数据的隐私敏感信息、机器学习模型的商业价值及其安全中的应用,所以机器学习模型在一定程度上是可以认为是机密的。但是越来越对机器学习服务提供商将机器学习作为一种服务部署在云上。笔者认为:这样部署机器学习即服务是存在安全隐患的,攻击者利用对模型的API可以窃取模型。
1.问题描述由于机器学习可能涉及到训练数据的隐私敏感信息、机器学习模型的商业价值及其安全领域中的应用(垃圾邮件过滤、恶意软件检测、流量分析等),所以机器学习模型在一定程度上是可以认为是机密的。但是,机器学习模型不断地被部署,通过公共访问接口访问模型, 例如机器学习即服务( Machine Learning as a service, MLaaS):用户可以在MLaaS 平台利用隐私敏感数据训练机器学习模型,并且将访问接口发布给其他用户使用,同时收取一定的费用。针对机器学习模型机密性和其公共访问的矛盾上,笔者提出了机器学习模型提取攻击:攻击者在没有任何关于该模型的先验知识(训练数据,模型参数,模型类型等)情况下,只利用公共访问接口对该模型的黑盒访问,从而构造出和目标模型相似度非常高的模型。
MLaaS提供商 白盒(其他用户是否可以付费下载模型) 是否商业化(用户发布模型其他用户使用) API是否输出置信度表1 MLaaS提供商的主要特点

图1 机器学习即服务商业化模式
2.攻击模型当用户在MLaaS平台上训练了自己的机器学习模型,并发布该模型给其他用户使用,并利用其他用户每次对模型的访问收取一定的费用,赚回自己在训练模型和标定数据投入时的成本。如果利用API访问目标模型的是攻击者,该攻击者利用对目标模型的尽量少地访问,试图在本地构造一个与目标模型相近甚至一致的模型。
笔者认为攻击可能出于以下目的窃取目标模型:
1. 想免费使用模型:模型训练者将模型托管在云上,通过提供API的方式来提供对模型的访问,通过对每次调用 API 的方式来收费,恶意的用户将企图偷取这个模型免费使用。这将破坏MLaaS的商业化模式,同时很可能存在这种情况:攻击者窃取模型所花的费用是低于模型训练者标定训练集和训练模型的成本。
2. 破坏训练数据隐私性:模型提取攻击会泄露训练数据的隐私,越来越多的研究工作表明:利用对模型的多次访问可以推断出训练数据信息,因为模型本身就是由训练数据所得到的,分析所提取到的模型,必然可以推断训练数据。具体可以参考这篇文章:Membership Inference Attacks against Machine Learning Models .
3.绕过安全检测:在越来越多的场景中,机器学习模型用于检测恶意行为,例如垃圾邮件过滤,恶意软件检测,网络异常检测。攻击者在提取到目标模型后,可以根据相关知识,构造相应的对抗样本,以绕过安全检测。参考文章:Evading Classifiers by Morphing in the Dark

图2 模型提取攻击场景
3.模型提取攻击笔者首先将引入针对输入返回置信度输出的场景,然后利用二分类让大家明白如何实现解方程攻击,进而讲解多分类场景中的方程求解攻击。由于决策树算法的置信度计算和逻辑回归(LR)、支持向量机(SVM)、神经网络(NN)算法不同,笔者还将讲解如何提取决策树模型。同时还进一步讨论当预测API隐藏置信度,只输出分类标签场景下的模型提取攻击。
3.1方程求解攻击 #p#分页标题#e#方程求解攻击针对逻辑回归(LR)、支持向量机(SVM)、神经网络(NN)算法,因为这些算法的模型不同于树形模型,这些模型都是函数映射,输出的置信度是函数的直接输出,模型的输入是函数的输入,该函数由一些列参数组成。也就是说,由置信度和输入数据可以构造方程,求解函数的参数就可以得到与目标相近的模型。
3.1.1二分类
笔者先从一个简单的场景引入,不考虑多项回归。假设受害者用户利用MLaaS的LR算法在其平台上训练了一个人脸识别模型,然后受害者想通过把模型发布给其他用户使用,并赚取一定的利润,然后受害者给很多用户发布其模型访问API,这些用户中有些人想通过对该模型的访问提取该二分类模型。

图3 简单二分类场景
于是该攻击者通过API访问模型,其返回是置信度信息。我们都知道模型只是由一系列参数决定。求解参数就可以实现模型提取。

在二分类中输出的置信度就是该函数的映射输出f(x),函数的参数是W,b其中W是一个n维向量,b是偏置。这些图象是92*112的灰度图,也就是特征维数为10304维。对sigmod函数求反函数就可以看出这是包含n+1个参数的函数,而且这些函数是线性函数。在特征空间足够大的,且攻击者随机访问的场景下,攻击者只需要随机访问模型n+1次,便可得到n+1个线性的方程组,求解这n+1个参数,便可得到目标模型。
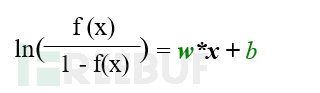
3.1.2 多分类
假设多分类要完成对c个类别分类,置信度则是输入在每个类别的概率分布,输出的置信度是n维向量。

图4 多分类分类场景
则其输出的置信度公式是:

其未知参数有c(n+1)(每个类别存在n+1个未知数),当然这个函数是非线性函数,也就是说,通过多次访问构建的方程组是非线性方程组,而且每个方程都是超越方程。关于这种方程组的求解可以利用梯度下降方法实现,构造一个损失函数为凸函数,转化为凸优化问题求解,求解全局最优解也就是该模型的参数。
3.2 决策树提取攻击决策树的置信度是在给定训练数据集,就已经确定了,每个叶子节点都有其对应的置信度值,笔者在此假设每个叶子节点都有不同的置信度值,也就说可以通过置信度标定不同的叶子节点:利用置信度作为决策树叶子节点的伪标识。同时很多MLaaS提供商做为了提升API访问的可访问性,MLaaS提供商的做法是即使输入的数据使部分特征依然可以得到输出结果。

图5 决策树示例
#p#分页标题#e#例如针对上述决策树:仅输入Color = Y,依然可以得到id6的置信度输出。不断在特征空间遍历, 便可以得到和置信度对应的叶子节点。例如我现在得到了id2的伪标识,通过只改其中的Color特征为B即可找到id3叶子节点。
主要基于两点假设前提:
1.设每个叶子节点都有不同的置信度值;
2.为了提升API访问的可访问性,MLaaS提供商的做法是即使输入的数据使部分特征依然可以得到输出结果。
笔者认为:隐藏置信度的输出仍然不能解决所存在的模型提取攻击:
1) 首先随机确定访问数据,对目标模型进行访问,并得到预测结果,
2) 利用这些数据集训练在本地训练机器学习模型
3) 找到离所训练机器学习模型分类边界很近的数据点,然后将这些数据对目标模型访问
4) 利用输入数据集和访问结果更新重训练模型,重复3 过程直到模型误差低于一定的值。

具体细节可以阅读我的GitHub代码。
4.总结MLaaS提供商所提供的灵活的预测API可能被攻击者用于模型提取攻击,这种商业化模式在笔者的角度是不安全的,本文提出了三种机器模型提取攻击方法,同时表明即使不输出置信度,只输出类标签,通过自适应地访问数据集的方法,模型提取攻击依然可行。MLaaS的部署应该谨慎考虑,同时MLaaS的安全部署有待进一步研究。