一、什么是Temporal Table
在《Apache Flink 漫谈系列 - JOIN LATERAL》中提到了Temporal Table JOIN,本篇就向大家详细介绍什么是Temporal Table JOIN。
在ANSI-SQL 2011 中提出了Temporal 的概念,Oracle,SQLServer,DB2等大的数据库厂商也先后实现了这个标准。Temporal Table记录了历史上任何时间点所有的数据改动,Temporal Table的工作流程如下:

上图示意Temporal Table具有普通table的特性,有具体独特的DDL/DML/QUERY语法,时间是其核心属性。历史意味着时间,意味着快照Snapshot。
二、ANSI-SQL 2011 Temporal Table示例
我们以一个DDL和一套DML示例说明Temporal Table的原理,DDL定义PK是可选的,下面的示例我们以不定义PK的为例进行说明:
1. DDL 示例
CREATE TABLE Emp
ENo INTEGER,
Sys_Start TIMESTAMP(12) GENERATED
ALWAYS AS ROW Start,
Sys_end TIMESTAMP(12) GENERATED
ALWAYS AS ROW END,
EName VARCHAR(30),
PERIOD FOR SYSTEM_TIME (Sys_Start,Sys_end)
) WITH SYSTEM VERSIONING
2. DML 示例
(1) INSERT
INSERT INTO Emp (ENo, EName) VALUES (22217, 'Joe')
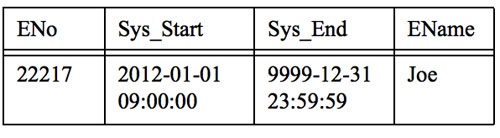
说明: 其中Sys_Start和Sys_End是数据库系统默认填充的。
(2) UPDATE
UPDATE Emp SET EName = 'Tom' WHERE ENo = 22217
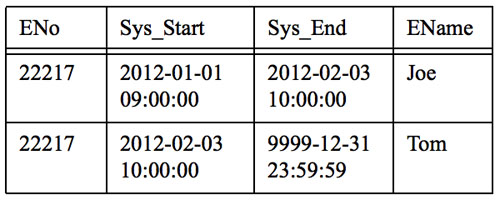
说明: 假设是在 2012-02-03 10:00:00 执行的UPDATE,执行之后上一个值"Joe"的Sys_End值由9999-12-31 23:59:59 变成了 2012-02-03 10:00:00, 也就是下一个值"Tom"生效的开始时间。可见我们执行的是UPDATE但是数据库里面会存在两条数据,数据值和有效期不同,也就是版本不同。
(3) DELETE (假设执行DELETE之前的表内容如下)
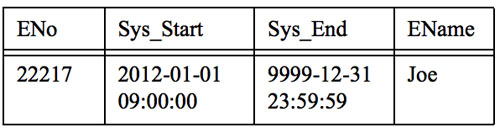
DELETE FROM Emp WHERE ENo = 22217

说明: 假设我们是在2012-06-01 00:00:00执行的DELETE,则Sys_End值由9999-12-31 23:59:59 变成了 2012-06-01 00:00:00, 也就是在执行DELETE时候没有真正的删除符合条件的行,而是系统将符合条件的行的Sys_end修改为执行DELETE的操作时间。标识数据的有效期到DELETE执行那一刻为止。
(4) SELECT
SELECT ENo,EName,Sys_Start,Sys_End FROM Emp
FOR SYSTEM_TIME AS OF TIMESTAMP '2011-01-02 00:00:00'
说明: 这个查询会返回所有Sys_Start <= 2011-01-02 00:00:00 并且 Sys_end > 2011-01-02 00:00:00 的记录。
三、SQLServer Temporal Table 示例
1. DDL
CREATE TABLE Department
(
DeptID int NOT NULL PRIMARY KEY CLUSTERED
, DeptName varchar(50) NOT NULL
, ManagerID INT NULL
, ParentDeptID int NULL
, SysStartTime datetime2 GENERATED ALWAYS AS ROW Start NOT NULL
, SysEndTime datetime2 GENERATED ALWAYS AS ROW END NOT NULL
, PERIOD FOR SYSTEM_TIME (SysStartTime,SysEndTime)
)
WITH (SYSTEM_VERSIONING = ON);
执行上面的语句,在数据库会创建当前表和历史表,如下图:

Department 显示是有版本控制的,历史表是默认的名字,我也可以指定名字如:SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DepartmentHistory)。
2. DML
(1) INSERT - 插入列不包含SysStartTime和SysEndTime列
INSERT INTO [dbo].[Department] ([DeptID] ,[DeptName] ,[ManagerID] ,[ParentDeptID])
VALUES(10, 'Marketing', 101, 1);
VALUES(10, 'Marketing', 101, 1);
执行之后我们分别查询当前表和历史表,如下图:
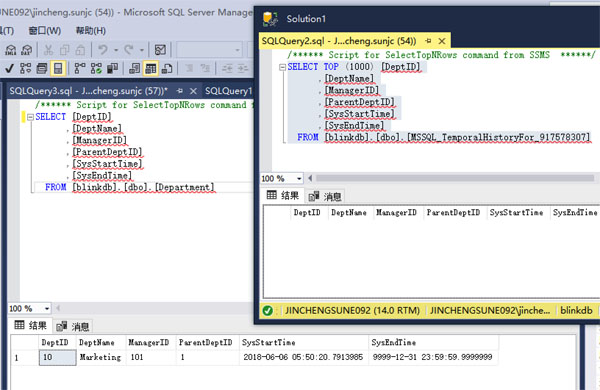
我们第一条INSERT语句数据值的有效时间是操作那一刻2018-06-06 05:50:20.7913985 到永远 9999-12-31 23:59:59.9999999,但这时刻历史表还没有任何信息。我们接下来进行更新操作。
(2) UPDATE
UPDATE [dbo].[Department] SET [ManagerID] = 501 WHERE [DeptID] = 10
执行之后当前表信息会更新并在历史表里面产生一条历史信息,如下:
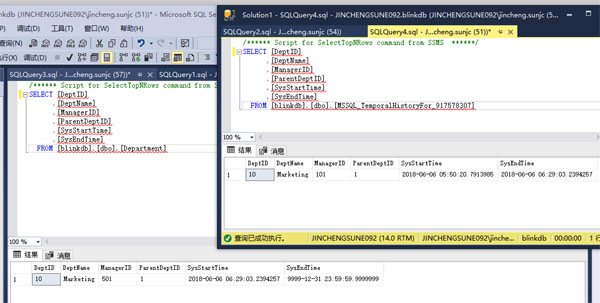
注意当前表的SysStartTime意见发生了变化,历史表产生了一条记录,SyStartTIme是原当前表记录的SysStartTime,SysEndTime是当前表记录的SystemStartTime。我们再更新一次:
UPDATE [dbo].[Department] SET [ManagerID] = 201 WHERE [DeptID] = 10
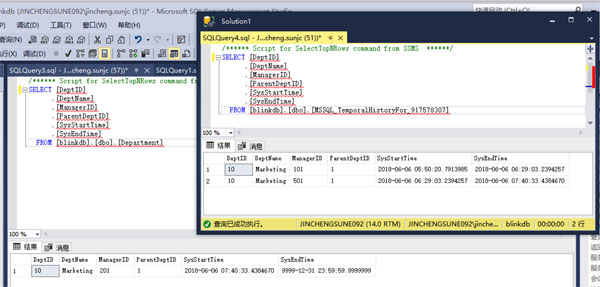
到这里我们了解到SQLServer里面关于Temporal Table的逻辑是有当前表和历史表来存储数据,并且数据库内部以StartTime和EndTime的方式管理数据的版本。
(3) SELECT
SELECT [DeptID], [DeptName], [SysStartTime],[SysEndTime]
FROM [dbo].[Department]
FOR SYSTEM_TIME AS OF '2018-06-06 05:50:21.0000000' ;
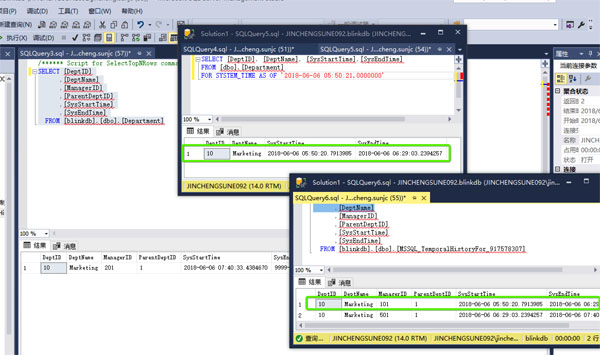
SELECT语句查询的是Department的表,实际返回的数据是从历史表里面查询出来的,查询的底层逻辑就是 SysStartTime <= '2018-06-06 05:50:21.0000000' and SysEndTime > '2018-06-06 05:50:21.0000000' 。
四、Apache Flink Temporal Table
我们不止一次的提到Apache Flink遵循ANSI-SQL标准,Apache Flink中Temporal Table的概念也源于ANSI-2011的标准语义,但目前的实现在语法层面和ANSI-SQL略有差别,上面看到ANSI-2011中使用FOR SYSTEM_TIME AS OF的语法,目前Apache Flink中使用 LATERAL TABLE(TemporalTableFunction)的语法。这一点后续需要推动社区进行改进。
1. 为啥需要 Temporal Table
我们以具体的查询示例来说明为啥需要Temporal Table,假设我们有一张实时变化的汇率表(RatesHistory),如下:
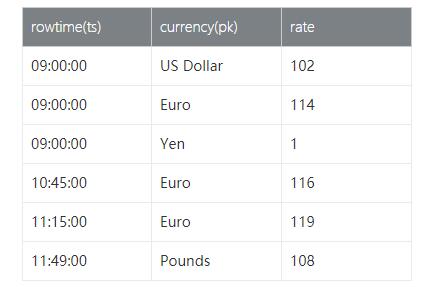
RatesHistory代表了Yen汇率(Yen汇率为1),是不断变化的Append only的汇率表。例如,Euro兑Yen汇率从09:00至10:45的汇率为114。从10点45分到11点15分是116。
假设我们想在10:58输出所有当前汇率,我们需要以下SQL查询来计算结果表:
SELECT *
FROM RatesHistory AS r
WHERE r.rowtime = (
SELECT MAX(rowtime)
FROM RatesHistory AS r2
WHERE rr2.currency = r.currency
AND r2.rowtime <= '10:58');
相应Flink代码如下:
定义数据源-genRatesHistorySource
def genRatesHistorySource: CsvTableSource = {
val csvRecords = Seq(
"rowtime ,currency ,rate",
"09:00:00 ,US Dollar , 102",
"09:00:00 ,Euro , 114",
"09:00:00 ,Yen , 1",
"10:45:00 ,Euro , 116",
"11:15:00 ,Euro , 119",
"11:49:00 ,Pounds , 108"
)
// 测试数据写入临时文件
val tempFilePath =
writeToTempFile(csvRecords.mkString("$"), "csv_source_", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("rowtime","currency","rate"),
Array(
Types.STRING,Types.STRING,Types.STRING
),
fieldDelim = ",",
rowDelim = "$",
ignoreFirstLine = true,
ignoreComments = "%"
)
}
def writeToTempFile(
contents: String,
filePrefix: String,
fileSuffix: String,
charset: String = "UTF-8"): String = {
val tempFile = File.createTempFile(filePrefix, fileSuffix)
val tmpWriter = new OutputStreamWriter(new FileOutputStream(tempFile), charset)
tmpWriter.write(contents)
tmpWriter.close()
tempFile.getAbsolutePath}
主程序代码
def main(args: Array[String]): Unit = {
// Streaming 环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(env)
//方便我们查出输出数据
env.setParallelism(1)
val sourceTableName = "RatesHistory"
// 创建CSV source数据结构
val tableSource = CsvTableSourceUtils.genRatesHistorySource
// 注册source
tEnv.registerTableSource(sourceTableName, tableSource)
// 注册retract sink
val sinkTableName = "retractSink"
val fieldNames = Array("rowtime", "currency", "rate")
val fieldTypes: Array[TypeInformation[_]] = Array(Types.STRING, Types.STRING, Types.STRING)
tEnv.registerTableSink(
sinkTableName,
fieldNames,
fieldTypes,
new MemoryRetractSink)
val SQL =
"""
|SELECT *
|FROM RatesHistory AS r
|WHERE r.rowtime = (
| SELECT MAX(rowtime)
| FROM RatesHistory AS r2
| WHERE rr2.currency = r.currency
| AND r2.rowtime <= '10:58:00' )
""".stripMargin
// 执行查询
val result = tEnv.SQLQuery(SQL)
// 将结果插入sink
result.insertInto(sinkTableName)
env.execute()
}
执行结果如下图:

结果表格化一下:
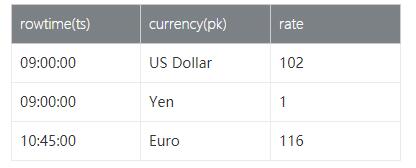
Temporal Table的概念旨在简化此类查询,加速它们的执行。Temporal Table是Append Only表上的参数化视图,它把Append Only的表变化解释为表的Changelog,并在特定时间点提供该表的版本(时间版本)。将Applend Only表解释为changelog需要指定主键属性和时间戳属性。主键确定覆盖哪些行,时间戳确定行有效的时间,也就是数据版本,与上面SQL Server示例的有效期的概念一致。
在上面的示例中,currency是RatesHistory表的主键,而rowtime是timestamp属性。
2. 如何定义Temporal Table
在Apache Flink中扩展了TableFunction的接口,在TableFunction接口的基础上添加了时间属性和pk属性。
(1) 内部TemporalTableFunction定义如下:
class TemporalTableFunction private(
@transient private val underlyingHistoryTable: Table,
// 时间属性,相当于版本信息
private val timeAttribute: Expression,
// 主键定义
private val primaryKey: String,
private val resultType: RowTypeInfo)
extends TableFunction[Row] {
...}
(2) 用户创建TemporalTableFunction方式
在Table中添加了createTemporalTableFunction方法,该方法需要传入时间属性和主键,接口定义如下:
// Creates TemporalTableFunction backed up by this table as a history table.
def createTemporalTableFunction(
timeAttribute: Expression,
primaryKey: Expression): TemporalTableFunction = {
...}
用户通过如下方式调用就可以得到一个TemporalTableFunction的实例,代码如下:
val tab = ...
val temporalTableFunction = tab.createTemporalTableFunction('time, 'pk)
...
3. 案例代码
(1) 需求描述
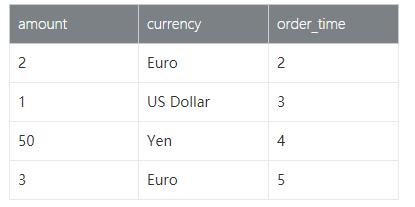
#p#分页标题#e#假设我们有一张订单表Orders和一张汇率表Rates,那么订单来自于不同的地区,所以支付的币种各不一样,那么假设需要统计每个订单在下单时候Yen币种对应的金额。
(2) Orders 数据
(3) Rates 数据
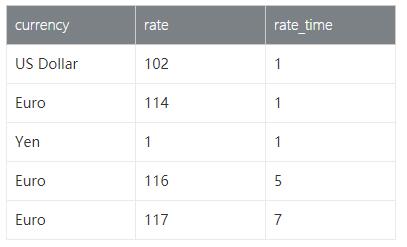
(4) 统计需求对应的SQL
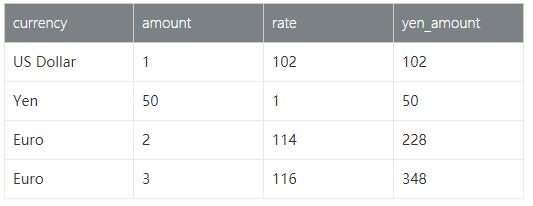
SELECT o.currency, o.amount, r.rate
o.amount * r.rate AS yen_amount
FROM
Orders AS o,
LATERAL TABLE (Rates(o.rowtime)) AS r
WHERE r.currency = o.currency
(5) 预期结果
4. Without connnector 实现代码
object TemporalTableJoinTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(env)
env.setParallelism(1)
// 设置时间类型是 event-time env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 构造订单数据
val ordersData = new mutable.MutableList[(Long, String, Timestamp)]
ordersData.+=((2L, "Euro", new Timestamp(2L)))
ordersData.+=((1L, "US Dollar", new Timestamp(3L)))
ordersData.+=((50L, "Yen", new Timestamp(4L)))
ordersData.+=((3L, "Euro", new Timestamp(5L)))
//构造汇率数据
val ratesHistoryData = new mutable.MutableList[(String, Long, Timestamp)]
ratesHistoryData.+=(("US Dollar", 102L, new Timestamp(1L)))
ratesHistoryData.+=(("Euro", 114L, new Timestamp(1L)))
ratesHistoryData.+=(("Yen", 1L, new Timestamp(1L)))
ratesHistoryData.+=(("Euro", 116L, new Timestamp(5L)))
ratesHistoryData.+=(("Euro", 119L, new Timestamp(7L)))
// 进行订单表 event-time 的提取
val orders = env
.fromCollection(ordersData)
.assignTimestampsAndWatermarks(new OrderTimestampExtractor[Long, String]())
.toTable(tEnv, 'amount, 'currency, 'rowtime.rowtime)
// 进行汇率表 event-time 的提取
val ratesHistory = env
.fromCollection(ratesHistoryData)
.assignTimestampsAndWatermarks(new OrderTimestampExtractor[String, Long]())
.toTable(tEnv, 'currency, 'rate, 'rowtime.rowtime)
// 注册订单表和汇率表
tEnv.registerTable("Orders", orders)
tEnv.registerTable("RatesHistory", ratesHistory)
val tab = tEnv.scan("RatesHistory");
// 创建TemporalTableFunction
val temporalTableFunction = tab.createTemporalTableFunction('rowtime, 'currency)
//注册TemporalTableFunction
tEnv.registerFunction("Rates",temporalTableFunction)
val SQLQuery =
"""
|SELECT o.currency, o.amount, r.rate,
| o.amount * r.rate AS yen_amount
|FROM
| Orders AS o,
| LATERAL TABLE (Rates(o.rowtime)) AS r
|WHERE r.currency = o.currency
|""".stripMargin
tEnv.registerTable("TemporalJoinResult", tEnv.SQLQuery(SQLQuery))
val result = tEnv.scan("TemporalJoinResult").toAppendStream[Row]
// 打印查询结果
result.print()
env.execute()
}
}
#p#分页标题#e#在运行上面代码之前需要注意上面代码中对EventTime时间提取的过程,也就是说Apache Flink的TimeCharacteristic.EventTime 模式,需要调用assignTimestampsAndWatermarks方法设置EventTime的生成方式,这种方式也非常灵活,用户可以控制业务数据的EventTime的值和WaterMark的产生,WaterMark相关内容可以查阅《Apache Flink 漫谈系列(03) - Watermark》。 在本示例中提取EventTime的完整代码如下:
import java.SQL.Timestamp
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.windowing.time.Time
class OrderTimestampExtractor[T1, T2]
extends BoundedOutOfOrdernessTimestampExtractor[(T1, T2, Timestamp)](Time.seconds(10)) {
override def extractTimestamp(element: (T1, T2, Timestamp)): Long = {
element._3.getTime
}
}
查看运行结果:
5. With CSVConnector 实现代码
在实际的生产开发中,都需要实际的Connector的定义,下面我们以CSV格式的Connector定义来开发Temporal Table JOIN Demo。
(1) genEventRatesHistorySource
def genEventRatesHistorySource: CsvTableSource = {
val csvRecords = Seq(
"ts#currency#rate",
"1#US Dollar#102",
"1#Euro#114",
"1#Yen#1",
"3#Euro#116",
"5#Euro#119",
"7#Pounds#108"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_rate", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("ts","currency","rate"),
Array(
Types.LONG,Types.STRING,Types.LONG
),
fieldDelim = "#",
rowDelim = CommonUtils.line,
ignoreFirstLine = true,
ignoreComments = "%"
)}
(2) genRatesOrderSource
def genRatesOrderSource: CsvTableSource = {
val csvRecords = Seq(
"ts#currency#amount",
"2#Euro#10",
"4#Euro#10"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_order", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("ts","currency", "amount"),
Array(
Types.LONG,Types.STRING,Types.LONG
),
fieldDelim = "#",
rowDelim = CommonUtils.line,
ignoreFirstLine = true,
ignoreComments = "%"
)
}
(3) 主程序代码
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
*
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.book.connectors
import java.io.File
import org.apache.flink.api.common.typeinfo.{TypeInformation, Types}
import org.apache.flink.book.utils.{CommonUtils, FileUtils}
import org.apache.flink.table.sinks.{CsvTableSink, TableSink}
import org.apache.flink.table.sources.CsvTableSource
import org.apache.flink.types.Row
object CsvTableSourceUtils {
def genWordCountSource: CsvTableSource = {
val csvRecords = Seq(
"words",
"Hello Flink",
"Hi, Apache Flink",
"Apache FlinkBook"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString("$"), "csv_source_", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("words"),
Array(
Types.STRING
),
fieldDelim = "#",
rowDelim = "$",
ignoreFirstLine = true,
ignoreComments = "%"
)
}
def genRatesHistorySource: CsvTableSource = {
val csvRecords = Seq(
"rowtime ,currency ,rate",
"09:00:00 ,US Dollar , 102",
"09:00:00 ,Euro , 114",
"09:00:00 ,Yen , 1",
"10:45:00 ,Euro , 116",
"11:15:00 ,Euro , 119",
"11:49:00 ,Pounds , 108"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString("$"), "csv_source_", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("rowtime","currency","rate"),
Array(
Types.STRING,Types.STRING,Types.STRING
),
fieldDelim = ",",
rowDelim = "$",
ignoreFirstLine = true,
ignoreComments = "%"
)
}
def genEventRatesHistorySource: CsvTableSource = {
val csvRecords = Seq(
"ts#currency#rate",
"1#US Dollar#102",
"1#Euro#114",
"1#Yen#1",
"3#Euro#116",
"5#Euro#119",
"7#Pounds#108"
)
// 测试数据写入临时文件
val tempFilePath =
#p#分页标题#e#FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_rate", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("ts","currency","rate"),
Array(
Types.LONG,Types.STRING,Types.LONG
),
fieldDelim = "#",
rowDelim = CommonUtils.line,
ignoreFirstLine = true,
ignoreComments = "%"
)
}
def genRatesOrderSource: CsvTableSource = {
val csvRecords = Seq(
"ts#currency#amount",
"2#Euro#10",
"4#Euro#10"
)
// 测试数据写入临时文件
val tempFilePath =
#p#分页标题#e#FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_order", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("ts","currency", "amount"),
Array(
Types.LONG,Types.STRING,Types.LONG
),
fieldDelim = "#",
rowDelim = CommonUtils.line,
ignoreFirstLine = true,
ignoreComments = "%"
)
}
/**
* Example:
* genCsvSink(
* Array[String]("word", "count"),
* Array[TypeInformation[_] ](Types.STRING, Types.LONG))
*/
def genCsvSink(fieldNames: Array[String], fieldTypes: Array[TypeInformation[_]]): TableSink[Row] = {
val tempFile = File.createTempFile("csv_sink_", "tem")
if (tempFile.exists()) {
tempFile.delete()
}
new CsvTableSink(tempFile.getAbsolutePath).configure(fieldNames, fieldTypes)
}
}
运行结果如下 :

6. 内部实现原理
我们还是以订单和汇率关系示例来说明Apache Flink内部实现Temporal Table JOIN的原理,如下图所示:
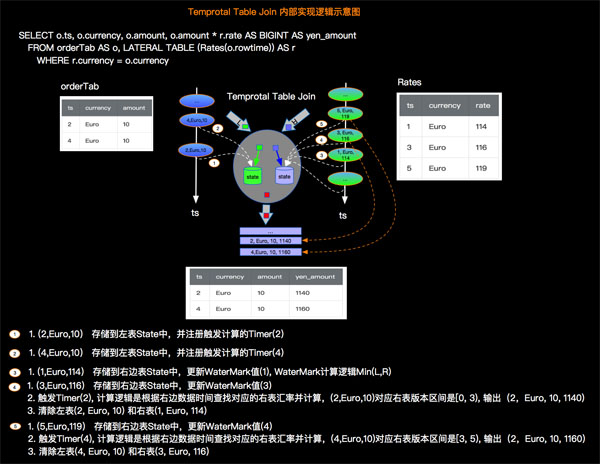
五、Temporal Table JOIN vs 双流JOIN vs Lateral JOIN
#p#分页标题#e#在《Apache Flink 漫谈系列(09) - JOIN算子》中我们介绍了双流JOIN,在《Apache Flink 漫谈系列(10) - JOIN LATERAL 》中我们介绍了 JOIN LATERAL(TableFunction),那么本篇介绍的Temporal Table JOIN和双流JOIN/JOIN LATERAL(TableFunction)有什么本质区别呢?
双流JOIN - 双流JOIN本质很明确是 Stream JOIN Stream,双流驱动。
LATERAL JOIN - Lateral JOIN的本质是Steam JOIN Table Function, 是单流驱动。
#p#分页标题#e#Temporal Table JOIN - Temporal Table JOIN 的本质就是 Stream JOIN Temporal Table 或者 Stream JOIN Table with snapshot。Temporal Table JOIN 特点单流驱动,Temporal Table 是被动查询。
1. Temporal Table JOIN vs LATERAL JOIN
从功能上说Temporal Table JOIN和 LATERAL JOIN都是由左流一条数据获取多行数据,也就是单流驱动,并且都是被动查询,那么Temporal JOIN和LATERAL JOIN最本质的区别是什么呢?这里我们说最关键的一点是 State 的管理,LATERAL JOIN是一个TableFunction,不具备state的管理能力,数据不具备版本特性。而Temporal Table JOIN是一个具备版本信息的数据表。
2. Temporal Table JOIN vs 双流 JOIN
Temporal Table JOIN 和 双流 JOIN都可以管理State,那么他们的本质区别是什么? 那就是计算驱动的差别,Temporal Table JOIN是单边驱动,Temporal Table是被动的查询,而双流JOIN是双边驱动,两边都是主动的进行JOIN计算。
3. Temporal Table JOIN改进
个人认为Apache Flink的Temporal Table JOIN功能不论在语法和语义上面都要遵循ANSI-SQL标准,后期会推动社区在Temporal Table上面支持ANSI-SQL的FOR SYSTEM_TIME AS OF标准语法。改进后的处理逻辑示意图:
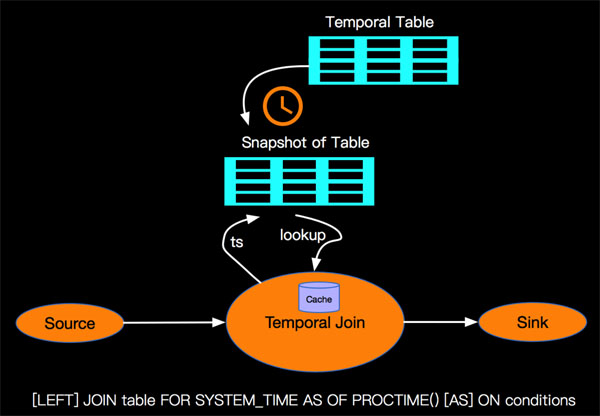
其中cache是一种性能考虑的优化,详细内容待社区完善后再细述。
六、小结
本篇结合ANSI-SQL标准和SQL Server对Temporal Table的支持来开篇,然后介绍目前Apache Flink对Temporal Table的支持现状,以代码示例和内部处理逻辑示意图的方式让大家直观体验Temporal Table JOIN的语法和语义。
关于点赞和评论
本系列文章难免有很多缺陷和不足,真诚希望读者对有收获的篇章给予点赞鼓励,对有不足的篇章给予反馈和建议,先行感谢大家!
#p#分页标题#e#作者:孙金城,花名 金竹,目前就职于阿里巴巴,自2015年以来一直投入于基于Apache Flink的阿里巴巴计算平台Blink的设计研发工作。