独立研究者 Karanbir Chahal 和 Manraj Singh Grover 与 IBM 的研究者 Kuntal Dey 近日发布了一篇论文,对深度神经网络的分布式训练方法进行了全面系统的总结,其中涉及到训练算法、优化技巧和节点之间的通信方法等。机器之心摘取了论文主干内容进行介绍,更多有关数学推理过程和算法步骤的解读请参阅原论文。

论文地址:https://arxiv.org/abs/1810.11787
深度学习已经为人工智能领域带来了巨大的发展进步。但是,必须说明训练深度学习模型需要显著大量的计算。在一台具有一个现代 GPU 的单台机器上完成一次基于 ImageNet 等基准数据集的训练可能要耗费多达一周的时间,研究者已经观察到在多台机器上的分布式训练能极大减少训练时间。近期的研究已经通过使用 2048 个 GPU 的集群将 ImageNet 训练时间降低至了 4 分钟。这篇论文总结了各种用于分布式训练的算法和技术,并给出了用于现代分布式训练框架的当前最佳方法。更具体而言,我们探索了分布式随机梯度下降的同步和异步变体、各种 All Reduce 梯度聚合策略以及用于在集群上实现更高吞吐量和更低延迟的最佳实践,比如混合精度训练、大批量训练和梯度压缩。
1. 引言
(1) 背景和动机
数据正以前所未有的规模生成。大规模互联网公司每天都会生成数以 TB 计的数据,这些数据都需要得到有效的分析以提取出有意义的见解 [1]。新兴的深度学习是一种用于执行这种分析的强大工具,这些算法在视觉 [2]、语言 [3] 和智能推理 [4] 领域的复杂任务上创造着当前最佳。不幸的是,这些算法需要大量数据才能有效地完成训练,而这又会耗费大量时间。第一个在 ImageNet 分类任务上取得当前最佳结果的深度学习算法在单个 GPU 上训练足足耗费了一周时间。在如今的时代,这样的速度已经完全不行了,因为现在的模型训练所使用的数据甚至会让 ImageNet 数据集的规模都相形见绌。现在存在以横向方式延展深度学习训练的内在需求,同时还要保证能够维持单 GPU 模型那样的准确度。理想情况下,这种训练的速度应该随机器数量的增加而线性增大,同时还要能容错以及能在高延迟网络条件下收敛。
(2) 分布式训练概述
神经网络的分布式训练可以通过两种方式实现:数据并行化和模型并行化。数据并行化的目标是将数据集均等地分配到系统的各个节点(node),其中每个节点都有该神经网络的一个副本及其本地的权重。每个节点都会处理该数据集的一个不同子集并更新其本地权重集。这些本地权重会在整个集群中共享,从而通过一个累积算法计算出一个新的全局权重集。这些全局权重又会被分配至所有节点,然后节点会在此基础上处理下一批数据。
模型并行化则是通过将该模型的架构切分到不同的节点上来实现训练的分布化。AlexNet [2] 是使用模型并行化的最早期模型之一,其方法是将网络分摊到 2 个 GPU 上以便模型能放入内存中。当模型架构过大以至于无法放入单台机器且该模型的某些部件可以并行化时,才能应用模型并行化。模型并行化可用在某些模型中,比如目标检测网络 [5],这种模型的绘制边界框和类别预测部分是相互独立的。一般而言,大多数网络只可以分配到 2 个 GPU 上,这限制了可实现的可扩展数量,因此本论文主要关注的是数据并行化。
本论文大致分为六个章节,第一节将介绍已有的优化训练算法。第二节将关注用于连接网络各节点的通信策略。第三节会探索一些具体技术,比如大批量训练、梯度压缩以及用于在低功耗设备和低速网络条件下实现有效训练的混合精度训练。第四节则会消化之前章节的信息,并选择出用于不同设定的最优的训练算法和通信原语。最后两节分别是未来研究方向和总结。
2. 分布式训练框架的组件
(1) 分布式训练算法
一个常用于分布式设定中的训练的常用算法是随机梯度下降(SGD),该算法将是我们进一步讨论中的核心点。需要指出一个重点,针对 SGD 提及的原则可以轻松地移植给其它常用的优化算法,比如 Adam [6]、RMSProp [7] 等等 [8]。分布式 SGD 可以大致分成两类变体:异步 SGD 和同步 SGD。
同步 SGD [9] 的目标是像分布式设置一样对算法进行复制,由此将网络中的节点紧密地耦合到一起。而异步 SGD [10] 则会通过降低节点之间的依赖程度而去除不同节点之间的耦合。尽管这种解耦能实现更大的并行化,但却不幸具有副作用,即稳定性和准确性要稍微差一些。人们已经提出了一些对异步 SGD 的修改方式,以期能缩小其与同步 SGD 的准确度差距。最近的研究趋势是扩展同步 SGD,更具体而言,即用大批量来训练网络已经得到了出色的结果。
#p#分页标题#e#较大的 mini-batch 大小具有一些优势,主要的一个优势是:在大 mini-batch 上训练时,模型能以更大的步幅到达局部最小值,由此能够加快优化过程的速度。但是在实践中,使用大批量会导致发散问题或「泛化差距」,即网络的测试准确度有时会低于在更小批量上训练的模型。最近的一些研究通过与批量大小成比例地调整学习率而实现了在大批量上的训练。实验发现,增加批量大小就相当于降低学习率 [11],而使用大批量进行训练还有一个额外的好处,即在训练中所要更新的总参数更少。通过将批量大小增大为 8096,以及使用线性学习率调整,已经能在一小时内完成在 ImageNet [12] 上的训练了 [9]。一种名为 LARS [13] 的技术支持使用高达 32k 的批量大小,[14] 中最近还与混合精度训练结合到了一起,使用 64k 的批量大小,在 4 分钟内成功完成了在 ImageNet 数据库上的训练。
(2) 节点之间的通信
分布式训练还有另一个重要组件,即节点之间的数据通信。多亏了 GFS [15] 和 Hadoop [16] 等一些分布式文件系统,这已经是一个成熟的研究主题了。以点对点的方式在节点之间实现高效且可感知带宽的通信需要集合通信原语(collective communication primitives)[17],这首先是在高性能计算(HPC)系统中引入的,之后由 [18] 带进了深度学习领域。TensorFlow [19] 和 PyTorch 等现代深度学习框架使用了这些原语来进行 All Reduce 过程,因为其允许在最优的时间内完成互连节点之间的梯度传输。All Reduce [17] 在实际应用中具有多种变体,比如 Ring All Reduce、递归减半或倍增(Recursive Halfing/Doubling)、Binary Blocks 算法。
在分布式训练中,为了实现有效的横向扩展,计算与通信的配置必须保证最优。如果通信步骤是高效的且能与各个机器的计算保持同步,即整个集群中的计算应该在大致同一时间结束,那么训练才是最优的。如果网络速度慢,那么节点之间的通信就会成为瓶颈。梯度压缩和混合精度训练都是很有潜力的技术,能够增大网络的整体吞吐量。近期的一项研究 [20] 已经发现使用周期性的学习率能将实现网络收敛所需的 epoch 数量降低 10 倍,使其成为了分布式训练方面一个很有潜力的研究方向。
(3) 随机梯度下降(SGD)的变体
随机梯度下降 [21] 是一种用于训练神经网络的优化算法。这是梯度下降的一种变体,是一种用于调整权重的算法,能在每次反向传播步骤之后使结果更接近最小值。SGD 不同于单纯的梯度下降,因为其处理的是 mini-batch,而非单个训练样本。其形式如下:
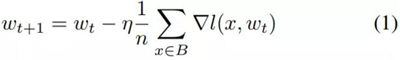
其中 w_(t+1) 是为当前批计算出的权重,n 是 mini-batch 中的训练样本的数量,∇l(x, w_t) 是为前一个训练样本计算出的梯度。
对于分布式的情况,SGD 大致可分为两类:异步 SGD 和同步 SGD。后续的章节会详细介绍这两种 SGD 和它们的变体。
3. 同步 SGD
同步 SGD 是一种分布式梯度下降算法,这是当前用于分布式训练的最常用优化方法之一。网络中的节点首先在它们的本地数据批上计算出梯度,然后每个节点都将它们的梯度发送给主服务器(master server)。主服务器通过求这些梯度的平均来累积这些梯度,从而为权重更新步骤构建出新的全局梯度集。这些全局梯度会通过使用与单机器 SGD 同样的配方来更新每个节点的本地权重。这整个过程都类似于在单台机器上通过单个数据 mini-batch 计算前向通过和反向传播步骤,因此同步 SGD 能保证收敛。但是同步 SGD 也存在一些局限性。
4. 异步 SGD
异步 SGD 是一种分布式梯度下降算法,允许在不同节点上使用不同的数据子集来并行地训练多个模型副本。每个模型副本都会向参数服务器请求全局权重,处理一个 mini-batch 来计算梯度并将它们发回参数服务器,然后参数服务器会据此更新全局权重。因为每个节点都独立计算梯度且无需彼此之间的交互,所以它们可以按自己的步调工作,也对机器故障更为稳健,即如果一个节点故障,其它节点还能继续处理,因此能消除由同步 SGD 引入的同步屏障(synchronization barrier)问题。
5. Ring 算法
[17] 中的 Ring All Reduce 结合了两种算法:scatter-reduce 和 all gather。

图 1:Ring 算法
scatter reduce 工作 p-1 个步骤,其中 p 是机器的数量。梯度向量被分为 p 块。

算法 1:Ring 算法的 scatter reduce
#p#分页标题#e#在 scatter reduce 过程结束后,每台机器都会有一部分最终结果。现在,每台机器只需将自己那部分结果广播给所有其它机器即可。这是使用 all gather 过程完成的,非常类似于 scatter gather,只是在接收数据上有些约简,这部分只是被看作是最终结果存储起来。

算法 2:Ring 算法的 all gather
6. 递归减半和倍增算法
[17] 中的递归距离倍增和向量减半算法使用了 4 种不同的原语,如下所示:
递归向量减半:向量在每个时间步骤减半。
递归向量倍增:分散在各个进程的向量的各个小块被递归式地收集起来,构建成一个大的向量。
递归距离减半:机器之间的距离在每次通信迭代后减半。
递归距离倍增:机器之间的距离在每次通信迭代后倍增。

图 2:减半和倍增算法
类似于 Ring 算法,这种 All Reduce 算法也由两个过程构成:scatter-reduce 和 all gather。该算法与 Ring 算法的不同之处是这些过程执行运算的方式。

算法 3:Scatter Reduce 向量减半算法

算法 4:All Gather 向量倍增算法
7. Binary Blocks 算法
Binary Blocks 算法是对递归距离倍增和向量减半算法的延展,它的目标是当机器数量不是 2 的乘方数时降低负载的不平衡程度。在用于非 2 的乘方数情况的原始算法中,有一些机器会被闲置在一旁,直到算法执行完成,之后它们会接收结果得到的向量。这种方法会导致某些情况下大量机器空闲,比如,对于 600 台机器构成的集群,会有 86 台机器空闲,进程只会在另外 512 台机器上执行。使用这种方法会出现很显著的负载不平衡。
Binary Blocks 算法是通过将机器的数量分成 2 的乘方数的多个模块来缓解这个问题。举个例子,对于 600 台机器构成的集群,可以分成 4 组,其中每组各有 2^9、2^6、2^4、2^3 台机器。

算法 5:Binary Blocks 主服务器算法

算法 6:Scatter Reduce 主客户端算法
8. 容错式 All Reduce
如果一个分布式集群是由低可靠度的设备构成的,那么一旦遇到机器故障就需要重启 All Reduce 算法。我们提出了一种容错式 Binary Blocks 算法,将 Raft 共识算法 [31] 的元素整合进了 All Reduce 中。该算法能应对机器故障,只要备份的副本仍可运行,就能继续执行。

图 3:Raft 算法
9. 调整批量大小
在实际训练深度神经网络时,学习率会随着训练经过多个 epoch 后而缓慢逐渐减小。这背后的直观思想是让权重在训练初期迈开更大的步子,随着模型接近收敛,步子也越来越小。这在实践中的效果相当好,并且能比使用固定学习率训练的模型达到更好的收敛程度。这也是一种很高效的方法,因为初期采用较大的学习率能够在使用更小的学习率微调之前取得很好的进展。但是,使用较大的批量大小进行训练是一个很有前景的研究方向,因为这能显著加速训练过程,能将训练时间从数天降至几分钟,正如 [9,14,13] 中证明的那样;[11] 的研究更是增强了这一趋势,通过实验证明增大批量大小就相当于降低学习率。
#p#分页标题#e#使用更大的批量大小进行训练的优势是模型执行的整体权重更新的数量更少,这能让训练速度更快,如图 4 所示。但是,相比于使用更小批量大小训练的模型,直接使用大批量进行训练也会出现问题,比如过早发散以及最终验证准确度更低。
![衰减学习率与增大批量大小 [11]](http://s4.51cto.com/oss/201811/06/eedc5d2d143f911432adc0f4447f0b17.jpg "衰减学习率与增大批量大小 [11]")
图 4:衰减学习率与增大批量大小 [11]
10. 张量融合
对于 ResNet 等某些常见的模型,研究者已经观察到为梯度计算的张量的大小是相当小的。更具体而言,用于卷积层的梯度张量大小比全卷积层的要小得多。这个现象是很突出的,因为通过线路发送少量数据可能会导致出现大量延迟,同时也没有充分利用网络带宽。一种解决这一问题的简单方法是张量融合 [14],简单来说就是将多个小张量融合到一起,形成一个至少超过某个最小大小的张量,之后再在网络中发送这个融合得到的张量。执行这种融合的好处是降低每台机器起始时间的负载以及降低网络流量的整体频率。这能让网络变得不再乱七八糟以及在最优时间内完成任务。但是,为小张量使用张量融合可能会导致 Ring All Reduce 变得低效而缓慢,[14] 提出了一种分层式 All Reduce,使用了多层主从设置,观察表明这种方法能带来更低的延迟。这种分层式 All Reduce 的工作方式是将所有机器分成不同的批,之后每一批都选择一个主节点来聚合梯度。这些主节点在它们自身上执行 Ring All Reduce,之后该主节点将更新后的梯度分配给它们各自的从节点。这种策略是通过降低批的数量来降低延迟开销,进而逐步降低 Ring All Reduce 的开销。使用张量融合能减少小网络的处理,并提升网络的整体速度,这是很值得推荐的。这种方法在 Horovord [38] 和腾讯的框架 [14] 等产业系统中得到了广泛的使用,使其成为了现代分布式训练框架中的重要一员。
11. 低精度训练
在 ImageNet 数据库 [12] 上训练一个 ResNet 模型 [29] 的最快时间目前是 4 分钟 [14]。在那项研究中,研究者使用低延迟的零副本 RDMA 网络连接了 2048 个 GPU,并且组合性地使用了 LARS 算法、混合 All Reduce 算法、张量融合和混合精度训练。混合 All Reduce 算法结合了 Ring All Reduce 和分层式的版本,并根据当前步骤的张量大小来进行切换。他们还使用了一种全新的方法才实现了这样的整体训练速度增益:混合精度训练 [39]。由此所带来的吞吐量和带宽效率增长将训练速度提升了 8 倍。顾名思义,混合精度训练是使用两种不同的数据类型来训练神经网络——更小的数据类型用于大多数运算,更大的数据类型用于对精度要求严格的运算。
神经网络最初是使用单精度或双精度数作为默认数据类型,因为这些数据类型在获取网络想要建模的任务的表征上表现很好。单精度数是 32 位浮点数,双精度数是 64 位浮点数。近期有研究表明通过在更低精度数据类型进行训练,可将神经网络的速度和大小降低 50%-80% [40, 41]。一种常用方法是使用 16 位浮点数来训练网络(FP16 训练),但与使用单精度训练的同样网络相比,这些网络的测试准确度会更差一些 [39]。这种情况的原因主要是权重更新步骤的精度更低。更具体而言,将低精度梯度与学习率相乘有时会导致数值溢出 16 位的范围,从而导致计算不正确,进而导致最终验证准确度损失。
混合精度训练 [39] 的目标是通过使用单精度(32 位)的权重主副本并以半精度(16 位)运行其它一切来解决这个问题。
混合精度训练能实现更高的吞吐量,从而能降低计算与通信瓶颈。但是,混合精度训练也存在一些需要注意的是像,即损失丢失和算术精度更低。
12. 梯度和参数压缩
扩展分布式训练过程的一个主要瓶颈是节点之间的模型权重和梯度通信具有很高的带宽成本。当在使用了联盟学习(federated learning)[42] 的设备(尤其是移动设备)上训练时,这个瓶颈会尤其显著,因为其存在网络带宽低和连接速度慢的问题。针对这一问题,研究者已经提出了多种用于高效利用网络带宽的方法。使用 SGD 的异步和同步变体允许节点各自独立地通信,同时还能实现并行化并将网络带宽利用提升到一定程度 [10,43,44];另外在梯度压缩上已经取得一些显著进展也很有希望 [45]。这些方法主要基于两大思想:量化和稀疏化。

算法 7:用于节点 k 上单纯的动量 SGD 的深度梯度压缩
13. 未来研究
#p#分页标题#e#过去几年来,分布式训练领域已经取得了很大的进展,并已为进一步创新做好了准备。相关领域目前正在增大 mini-batch 大小的限制,直到网络不会发散或降低同步 SGD 的最终验证准确度的程度,还在研究解决异步 SGD 的 stale 梯度和最终验证准确度降低的问题。在更低功耗的设备上进行训练已经以联盟学习(federated learning)[42] 的形式获得一些发展势头,也出现了一些用于安全和去中心化训练的现代深度学习框架构建模块。在消费级设备上训练有一些好处,其中之一是能够打造能基于消费者交互学习特定习惯的智能应用,而且通过在设备上存储数据和执行训练,还能保证用户的数据隐私。这类应用的一个案例是 Android Predictive Keyboard(安卓预测键盘),它能在设备上学习用于预测下一个词的小型个性化模型。在低功耗设备上训练的一个关键难题是可用的网络带宽和计算资源很少。高效的框架也许可以实现在手机和物联网设备上的大规模训练,从而实现便携式的深度学习应用。[54] 已经在低功耗设备上的分布式训练方面做出了一些出色的工作,其使用了强化学习算法来调度在异构式设备集群上的训练任务。在商品级设备上进行分布式训练需要在训练和通信方面进行多种优化。梯度压缩和混合精度训练是少数几种结果优良且很有希望的方向。整体而言,这个领域的研究方向很活跃且存在很多创新,并已经做好准备,即将成为更广泛智能应用的核心组件。
总结
我们介绍和总结了分布式训练框架的各个组件。为了打造一个高效且可扩展的分布式训练框架,我们推荐使用以下技术:
推荐使用同步 SGD 算法来进行训练,因为它有严格的收敛保证。
应该使用 Binary Blocks 算法来执行梯度累积的 All Reduce 流程,因为其运行时间更优。
为了有效地使用硬件和网络带宽,应该在框架中使用梯度压缩、量化和混合精度训练等多种技术。我们推荐组合式地使用深度梯度压缩和混合精度训练。
应该使用非常大的批量大小来进行训练,以最大化并行能力和最小化运行时间。我们推荐使用 LARS 算法,因为已有研究证明它能够以高达 64000 的批量大小足够稳健地训练网络。
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】
上一篇:SOC的四大弱点及其应对方案
下一篇:互联网架构,究竟为啥要做服务化?