栏目索引
相关内容
经过一个月的折腾,终于分家了。
原来的订单模块,库存模块,积分模块,支付模块......摇身一变,成为了一个个独立系统。

主人给这些独立的系统起了一个时髦的名字: 微服务!
有些微服务是主人的心头肉,他们“霸占”了一台或者多台机器,像我这个积分模块,哦不,是积分系统,不受人待见,只能委屈一下,和另外几个家伙共享一台机器了。
主人说我们现在是分布式的系统了,大家要齐心协力,共同完成原来的任务。
原来大伙都居住在一个JVM中,模块之间都是直接的函数调用,如今每个人对外提供的都是基于HTTP的API: 想要访问别人,需要准备好JSON数据,然后通过HTTP发送给过去,人家处理以后,再发送一个JSON的响应。
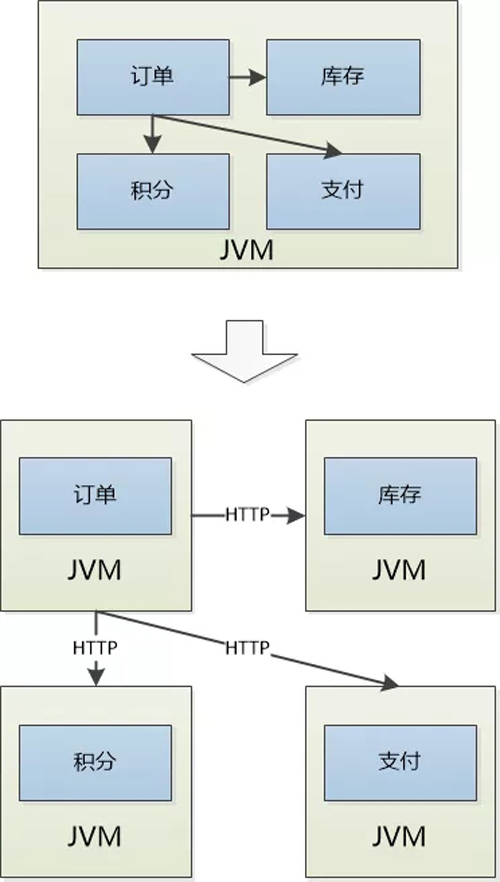

真是麻烦,哪怕一次最简单的沟通都要跨越网络了。
重复执行
提起这网络我心里就来气, 想想原来大家都在一个进程中,那调用速度才叫爽。 现在可好,一是慢如蜗牛,二是不可靠,时不时就会出错。
30毫秒以前,订单这家伙调用我的接口,要给一个叫做U0002的用户增加200积分,我很乐意地执行了。
POST /xxx/BonusPoint/U0002
{"value:200"}
可是,当我想把积分的调用结果告诉订单系统的时候,发现网络已经断开,发送失败。 怎么办? 我想反正已经执行过了,Forget it !
可是订单那小子对我这边的情况一无所知,心里琢磨着也许是我这边出错了, 死心眼的他又发起了同样的调用。
对我而言,这个新的调用和之前的那个没有一毛钱关系。(不要忘了,HTTP是没有状态的)我就老老实实地再执行一遍。
结果可想而知,用户"U0002"的积分被无端地增加了两次!
订单小伙说:“这样不行啊,你得记住我曾经发起过调用,这样第二次就不用执行了!”
“开玩笑!HTTP是无状态的, 我怎么可能记录你曾经的调用?”
“我们可以增加一点儿状态, 每次调用,我给你发一个Transaction ID, 简称TxID,你处理完以后, 需要把这个TxID,UserID, 积分等信息给保存到数据库中。”
POST /xxx/BonusPoint/U0002
{"txid":"T0001","value":"200"}
我说:“这有什么用?”
“每次执行的时候,你都可以从数据库中查一下啊,如果看到同样的TxID已经存在了,那就说明之前执行过,就不用重复执行了。如果不存在,才真正去执行。”
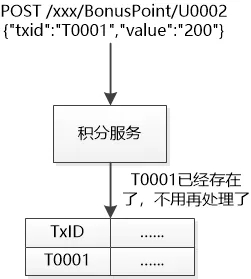
这倒是一个好主意,虽然我增加了一点工作量,需要一点额外的存储空间(正好借此机会要一个好点儿的服务器!),但是却有一个很好的特性: 对于同一个TxID,无论调用多少次,那执行效果就如同执行了一次,肯定不会出错。
后来我们才知道,人类把这个特性叫做幂等性。
一般来说,在后端数据不变的情况下,读操作都是幂等的,不管读取多少次,得到的结果都是一样的。 但是写操作就不同了,每次操作都会导致数据发生变化。要想让一个操作可以执行多次,而没有副作用,一定得想办法记录下这个操作执行过没有。
遗漏执行
我把新API告诉大家: 一定要给我传递过来一个TxID啊, 否则别怪我不处理!
这一天,我接收到了两个HTTP的调用,第一次是这样的:
POST /xxx/BonusPoint/U0002
{"txid":"T0010","value":"200"}
于是我很高兴地执行了,并且把T0010这个txid给保存了下来。
然后第二个调用又来了, 和第一个一模一样:
POST /xxx/BonusPoint/U0002
{"txid":"T0010","value":"200"}
我用T0010一查,数据库已经存在,我就知道,不用再处理了, 直接告诉对方:处理完成。
没想到的是, 用户很快就抱怨了:为什么我增加了两次积分(每次200),但实际上只增加了一次呢?
这肯定不是我的锅, 我这边没有任何问题,一切按照设计执行。 我说:“刚才是谁发起的调用,检查下调用的日志!”
调查了调用方的日志才发现,那两次调用是两个系统发出的!
碰巧,这两个系统生成了相同的TxID : T0010 , 这就导致我认为是同一个调用的两次尝试, 实际上这是这是完全不同的两次调用。
真相大白,TxID是罪魁祸首,可见这个TxID在整个分布式的系统中不能重复,一定得是唯一的才行。
分布式ID
怎么在一个分布式的系统中生成为一个唯一的ID呢?
#p#分页标题#e#订单小伙说:“这很简单,我们使用UUID就可以了,UUID中包含了网卡的MAC地址,时间戳,随机数等信息, 从时间和空间上保证了唯一性, 肯定不会重复。 ”
UUID可以在本机轻松生成,不用再发起什么远程调用,效率极高。
844A6D2B-CF7B-47C9-9B2B-2AC5C1B1C56B
我说:“只是这长达128位数字和字母显得很凌乱,没法排序,也无法保证有序递增(尤其是在数据库中,有序的ID更容易确定位置)。”
大家纷纷点头,UUID被否定。
MySQL提议:“你们竟然把我忘了! 我可以支持自增的(auto_increment)列啊, 天然的ID啊,同志们,绝对可以保证有序性。”
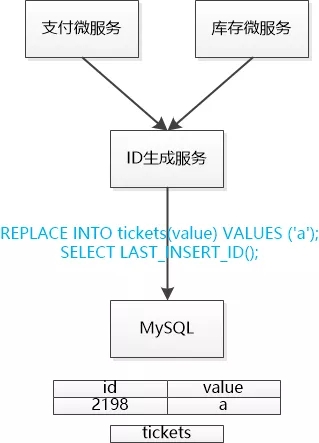
“啊? 用数据库? 你万一要是罢工了怎么办? 我们没有ID可用,什么事儿都干不成了!” 大家一想到慢吞吞的老头儿,让大家去依赖它,把生杀大权交到它的手上,都有点不乐意。
Ngnix说:“你们怕他罢工,就多弄几个MySQL呗,比如2个。
第一个的初始值是1,每次增加2,它产生的ID就是 1, 3, 5,7......
第二个的初始值是2,每次也增加2,它产生的ID就是 2,4,6,8,10......
再弄一个ID生成服务,如果一个MySQL罢工了,就访问另外一个。”
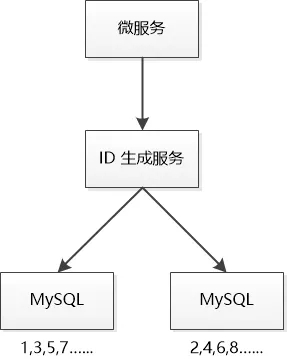
“如果这个ID生成服务也完蛋了呢?” 有人问道。
“那可以多部署几个ID生成服务啊, 这不就是你们微服务的优势所在吗?” Nginx反问。
Ngnix不亏是搞负载均衡的,这个方法可是相当地妙, 不但提高了可用性, ID还能保持趋势递增。
“可是,我每次需要一个TxID,都需要访问一次数据库啊,这该多慢啊!” 订单小伙说道。
负责缓存的Redis说道:“不要每次都访问数据库,学我,缓存一些数据到内存中。”
“缓存? 怎么缓存?”
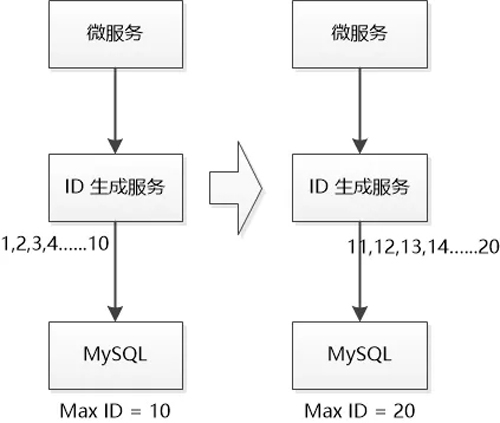
Redis 说:“每次访问数据库的时候,可以获取一批ID,比如10个, 然后保存的内存中,这样别人就可以直接使用,不用访问数据库了, 当然,数据库需要记录下当前的最大ID是多少。”
假设初始的最大ID是1 , 获取10个ID, 即 1,2,3......10 ,保存到内存中, 此时 最大ID变成10。
下次再获取10个,即11,12,13......20 , 最大ID变成20。
“可是,你这个唯一的MySQL罢工了,系统还是要停摆啊!” 我说。
Ngnix说:“这种事情很简单,多加一个MySQL,弄一个一主一从的结构, 嗯,如果数据没有及时从Master复制到Slave的时候,Master就罢工了,此时Slave的中的Max ID就不是最新的,那接下来就可能出问题,也许可以搞一个双主的结构......”
唉,搞一个分布式的唯一ID这么复杂啊!
Ngnix在那里嘟嘟囔囔,大家都没有注意到,一个新的服务上线了,一上来就说:“嗨,大家好,我是snowflake......”

【本文为51CTO专栏作者“刘欣”的原创稿件,转载请通过作者微信公众号coderising获取授权】
戳这里,看该作者更多好文
【编辑推荐】
一个想休息的线程:JVM到底是怎么处理锁的?怎么不让我阻塞呢?
Spring Cloud构建微服务架构:分布式配置中心【Dalston版】
Google 的后端工程师都开始写小程序了?反编译 “猜画小歌”看看
微服务化很难?一文简单理解服务拆分与服务发现
JVM和Python解释器的硬盘夜话
上一篇:单屏页面响应式适配玩法