栏目索引
相关内容

最近因为工作需要对VLDB的一些论文进行了阅读。其中包括谷歌新发表的F1数据库的分析。解读谷歌论文一直都是不太容易的。因为谷歌向来都是说一半藏一半。这篇论文相对来说还是写的比较开放的,还是不能免俗。
这篇论文是谷歌2013年VLDB发表的F1:A Distributed SQL Database that Scales的后续,全面阐述了谷歌的F1数据库这些年来发展的情况。本文详细讨论一下这篇论文。
F1和竞争对手的背景知识
我们先回顾一下F1的历史。F1是一个支持多数据源的数据查询系统。它最初诞生于谷歌的广告部门。其一开始的主要目的是为了取代当时广告系统的mySQL集群。F1从一开始就定位成一个查询引擎,实行严格的计算存储分离原则。底下对接的存储系统则是当时并行开发的BigTable下一代产品Spanner。
之后2014年VLDB谷歌发表了Mesa—一个全球跨多数据中心的数据仓库系统。Mesa成为F1主要对接的第二个系统。F1发展到今天,已经成为了一个可以支持多个数据源,从CSV文件到BigTable到Spanner等的数据联邦查询(federated query)的系统。
经过了这么多年的发展之后,谷歌内部也形成了很多套数据处理系统。这些数据库系统本身有很强的竞争关系。换句话来说,我能从你这里抢过来一个客户,我的队伍就会更庞大。F1作为一个在谷歌内部不断发展壮大的系统,也是这种竞争关系中的胜出者。
了解这些数据库的历史和服务对象,对我们更深刻的理解F1系统的业务支持和技术选型,有很重要的作用。所以下面我对和理解F1这篇论文相关的一些谷歌其他数据库系统做一个介绍。
F1最初的定位是为谷歌的Ads部门取代mySQL集群而开发的。Spanner作为F1的底层系统,是一个支持事务处理(使用2 phase locking实现)的存储层,F1作为计算引擎存在。
但是Spanner队伍本身在开发完存储层以后,自己也开始作数据查询,开发了一个内部叫做Spandex的查询系统。Spanner怎么样演变成为一个完整的SQL系统论文发表于SIGMOD 2017。这导致了F1和Spanner之间有了竞争关系。时至今日,这两个队伍在谷歌内部的竞争关系依旧激烈。
Dremel是谷歌内部的一个数据仓库系统。谷歌对外商用化了Dremel,取名叫BigQuery。Dremel采用了半结构化的数据模型,存储格式是列式存储,其第一代格式是ColumnIO。
对外商用化以后引入了第二代格式Capactior。这两种格式都是F1支持的外部数据源。Dremel在谷歌内部异常的成功。迄今为止,BigQuery依然是谷歌云上最为成功的大数据产品。
Flume是谷歌内部MapReduce框架的升级产品。最初只在Java上开发,所以最初叫做FlumeJava,后来也有C++的版本。Flume改变了MapReduce框架里面写Map和Reduce的开发模式,引入了更多高层的API,它的开发模式比较像Spark。
在底层的执行环境下,Flume也改变了MapReduce的死板模式,可以支持Map-Reduce-Reduce这样的模式。它的好处是可以很灵活的写出各种各样的数据处理pipeline,坏处是简单的事情也要写很多的code,不像SQL那么简单。
F1的业务定位
F1系统支持三种不同的数据查询方式:
1. 只影响几条记录的OLTP 类型的查询
2. 低延迟的涉及到大量数据的OLAP查询
3. 大规模的ETL Pileline
F1的论文并没有给出对这三种不同的数据查询方式的分析。我结合2013年的F1论文和其他背景知识来给大家分析一下F1支持者三种不同数据查询方式的原因。
OLTP类型的查询起源于F1的最初目标:在广告业务中取代mySQL集群。根据2013年的F1论文,其OLTP的支持是有局限性的。在F1系统里的一个OLTP查询是读若干操作跟着0到1个写操作。F1系统的OLTP的事务处理能力,依赖于Spanner底层对事物处理的支持。
在2018年的论文里,作者没有对OLTP类型的查询进行详细的介绍。但是按照常理分析,一个无状态的查询引擎如果需要支持事务处理,离不开底层存储对事物的支持。所以F1引擎显然无法做到对任何它连接的数据源都可以实现事务处理。鉴于Spanner自己也实现了数据查询引擎,并且也有对事物处理的支持。在这方面F1和Spanner有明确的竞争关系。
低延迟并且涉及到大量数据的OLAP查询,其定位很类似于BigQuery。其实现上也颇有BigQuery实现的方式,主要通过pipeline的方式来查询并返回数据结果。
从本文Related work介绍自己和谷歌内部其他竞争对手的分析看,早年谷歌的一个叫做Tenzing的系统关停以后,业务被迁移到了Bigquery或者F1。我们可以理解在这一类查询上BigQuery和F1是竞争对手关系。从实际表现来看,BigQuery更成功。
#p#分页标题#e#早年,在谷歌内部,大规模的ETL Pipeline主要靠一系列的MapReduce任务来实现。有了Flume之后,这些业务陆续都迁移到了Flume上。但是Flume是一个很不好用的系统,做一个简单的数据查询也需要很长的代码。这篇论文里,作者明确提到F1在一些业务上成功的取代了Flume。
结合上述分析,我们可以简单的下一个结论。在谷歌内部F1的OLTP业务主要是F1早年的目标。F1在OLTP业务上依赖于Spanner的支持。而后来Spanner自己也发展出了类似的引擎。这和我听说的F1主要用于广告部门,而非广告部门则大量使用Spanner不矛盾。
在低延迟OLAP查询上,F1主要竞争对事是BigQuery。以BigQuery今天的成功态势。F1应该只在自己的大本营广告部门有业务基础。
Flume在谷歌内部是好坏参半的一个系统。比MapReduce好,但是不好用。F1在ETL业务上发力,可以抢占一部分市场。从技术架构上来看,如何实现更好用的ETL是F1团队2018年论文里比较关键的技术。
F1的系统架构
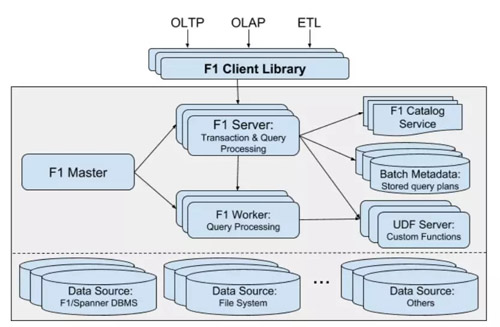
下图是2018年论文里,F1系统的架构图:
下图是2013年论文里的F1系统架构图:
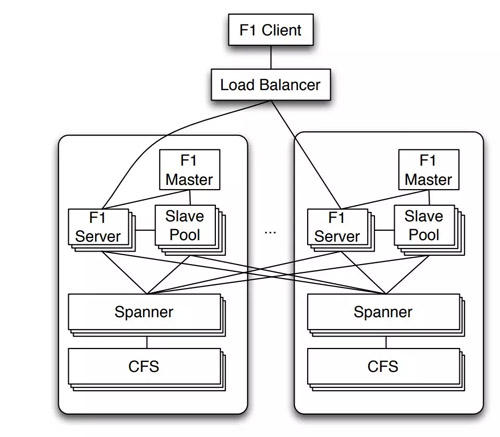
F1系统可以部署到不同的数据中心去,但是每个数据中心有一套完整的计算集群。集群包括1个F1Master。它是通过选举产生的非单节点服务,每个数据中心唯一。它主要是监控查询的执行和管理所有的F1Server。系统包括若干个F1 Server,这些F1 Server是实际处理查询请求的。
此外还有一个F1 worker pool。当一个查询需要并行执行的时候,这些worker用来执行并行查询,对应的F1 server成为这个查询的coordinator。Worker在2013年的系统架构图里叫做Slave。其实只是名字不同。有关F1 Server的实际职责在2013年的论文里讲的更清楚一些。
系统还有一个Catalog Service和一个UDF Server。这些东西相对于2013年论文里的系统架构师新增加的东西。Catalog Service是元数据服务,它可以不同数据源里面的数据都定义成外表。我们可以看到2013年的系统架构里面,数据源只有Spanner,但是2018年的论文里,数据源就多样化了。所以Catalog Service是F1发展过程中成为一个多数据源联邦查询引擎的必要服务。
UDF Server是F1在2018年论文里揭示的一个新东西。其主要意义还是实现对ETL的支持和Flume的取代。我们在后面部分详细介绍。
F1的查询模式
F1的查询模式简单可以分为交互式的和非交互式的。综合2013年和2018年的论文来看。交互式的执行主要是针对只影响几条记录的OLTP 类型的查询和低延迟的涉及到大量数据的OLAP查询。系统对于这两类查询的执行通过F1 Server进行。
F1 Server编译并优化查询之后会生成执行计划。执行计划有两种:单线程执行和并行执行。前者由Server直接执行。后者Server成为整个并行查询的Coordinator,通过RPC调用worker来执行。文章讨论了系统的分区策略和如何提高系统性能的一些决策,主要是针对data skew和non-optional access pattern。其做法是分布式数据库常见的做法。有兴趣的可以去读论文。这里就不再展开了。
作者提到,交互式的执行在大概一个小时内还比较稳定,否则有可能会失败。按照论文的说法,F1的分布式交互执行本身不具备fault tolerance,但是F1 client有重试功能。对于一个成熟的系统,这多少是个遗憾。
非交互式的执行方式主要用于时间很长的查询。它借助于谷歌的MapReduce框架。查询被编译成查询计划(query plan)后存到Query Registry里。Query Registry是一个全球跨数据中心分布的Spanner数据库,用来追踪所有的batch模式下查询的元数据。此外还有一个全球跨数据中心的Query Distributor服务,后者把查询计划分配给一个数据中心,数据中心用MapReduce框架执行这个查询。
在MapReduce的查询框架里,F1的优化引入了Map-Reduce-Reduce的模式,这个和Map-Reduce的框架不符合。F1团队的解决方式是把这个翻译成Map-Reduce后跟一个Map-Reduce任务。这显然不是最高效的办法。由此可见,长查询通过MapReduce来执行并非最有效的方式。而F1也无法摆脱执行框架的限制。
F1的优化器
F1的优化器的结构图如下。这是一个比较经典的查询优化流程。优化器从编译器获得AST作为输入,首先转换成一个逻辑查询计划,经过逻辑优化之后,再生成一个物理查询计划。这个查询计划最后被执行计划产生器产生出一个执行计划。
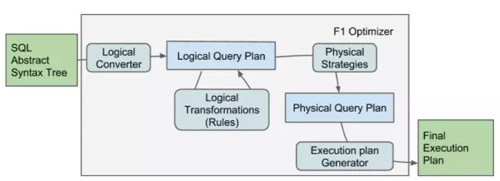
逻辑优化主要是通过关系代数的逻辑改写,把输入的逻辑查询计划变成一个根据heuristic来说最优的计划,常见的优化比如说predicate pushdown之类的都在这里执行。物理查询计划则是负责把逻辑计划翻译成物理计划。最候执行计划产生器会对物理计划进行分段,每个分段成为最后执行的单元,同时在执行单元之间插入exchange 操作符以实现对数据的重新分区。这里还会决定每个执行单元的并发度问题。
F1的优化器整体来看是比较原始的优化器。整个优化器完全基于rule,没有cost-base的优化。和常见的数据仓库系统来比,这方面需要很多提高。
F1的可扩展性
F1支持User-defined function(UDF),user-defined aggregate function (UDA)和table-value function(TVF)。这些都是数据库系统里面常见的扩展。这些用户定义的扩展可以用SQL或者LUA脚本来实现。基本上这些实现都是数据库里比较经典的实现方式。
但是F1里面比较特殊的是引入了UDF server的新东西。它主要用来实现更复杂的TVF。一个UDF server是一个服务,它可以用任何语言去实现,它给F1提供TVF的函数接口。这些接口F1除了在运行的时候会把对应的输入送进去并接收回来结果以外,还在查询编译的时候给编译器和优化器提供额外的信息。比如说输出的schema是什么,TVF是不是可以被分区以后在每个分区上单独去执行等等。
UDF server在文章中着墨很少,但是在我看来这是2018年的F1论文里相对于2013年的论文最重要的一个不同。有了UDF server才让复杂的ETL逻辑成为可能。UDF server也解决了数据库领域对UDF的老大难问题:资源管理的问题。如果说要我选一个最为亮眼的东西,我觉得是UDF server。
我相信谷歌的F1开发人员应该很清楚的意识到了UDF server的重要性,但是论文里基本上没有多写。不能不说这可能是故意为之。
使用UDF server使得F1支持复杂ETL成为可能。同时对于ETL里面标准的数据处理逻辑,可以通过写SQL的方式直接实现。同时因为UDF server是一个分开的service,UDF常见的资源管理老大难问题也被解决了。
总结
2018年的VLDB这篇F1论文讲述了谷歌F1数据库的架构和发展。F1现在发展成一个支持多数据源的多种数据功能的数据查询引擎。它的OLTP类的查询主要针对最初的任务,取代mySQL。它的低延时的OLAP查询主要和Dremel竞争。而它支持复杂ETL的目标主要是瞄准了Flume。
F1有三种执行模式:单线程,分布式交互式执行,基于MapReduce的非交互式执行。其中分布式交互执行没有故障恢复功能,是一个遗憾。基于MapReduce的非交互式执行的性能有进一步优化的空间。
F1的优化器是比较经典的数据库优化器,只实现了rule-base的优化,没有实现cost-base的优化。所以我想Join-reordering这样的优化还是做不了的。这个优化器相当简陋,有很多的提高空间。
在可扩展性方面,扩展方式UDF, UDA, TVF都是经典的数据库扩展方式。其UDF server是一个非常重要的发明。我认为在本文所有讲的东西里,也是唯一具有很大参考价值的东西。但是本文显然故意省略了这一块。
F1的体系架构和2013年比,还增加了一个元数据服务Catalog。Catalog在data lake的场景下有着很重要的作用。无论是对数据的发现还是共享都必不可缺。涉及到权限管理的时候,全局元数据服务的作用也是不可替代的。Cost-base的优化也需要基于元数据服务。非常遗憾的是F1对这个2018年论文里新增加的组件一字未提。
【本文为51CTO专栏作者“徐飞”的原创稿件,转载请通过作者微信公众号“飞总聊IT”获取联系和授权】
下一篇: 区块链应用发展与安全论坛上海分论坛召开