栏目索引
相关内容
张大胖学校的图书馆网站上线了,张大胖去浏览了一番,发现竟然没有按照关键字搜索图书的功能,大为吃惊之余,又隐约觉得机会来了: 我刚学完Web开发,其中也有数据库相关的知识,也许我可以实现这个功能啊!
想到此处,张大胖赶紧查找联系方式,抱着试试看的态度给图书馆的管理员发了一封电子邮件,表达了能实现这个搜索功能的信心和决心。

没想到真的收到回信了,管理员王老师让他在周四的下午2点半到图书馆3楼307聊一聊。
周四下午,张大胖沐浴更衣以后,如约而至。 经过一番寒暄和介绍,王老师正式进入主题:你打算怎么实现这个全文检索功能啊?
张大胖说:“我可以用SQL的 Like来实现。”
王老师笑了:“数据量小的时候Like还凑合,数据量一大,效率就非常低了。”
张大胖有点蒙:“那怎么办?”
王老师说:“得用inverted index才行。”
张大胖知道什么是index, 但是从来没有听说过inverted index,这是什么鬼?
王老师看到他迷茫的脸色,就知道这小子虽然勇气可嘉,但是技术还是有所欠缺,鼓励到:“这样吧,你回去研究研究inverted index, 然后再来实现这个全文检索功能。”
Inverted Index
张大胖灰溜溜地回到宿舍,赶紧拨号上网去查这个inverted index。
张大胖发现有很多人把他翻译成倒排索引,听起来虽然有点古怪,但实际上是一个非常简单的概念。 比如说有两篇文档:
文档1的内容:A computer is a device that can execute operations
文档2的内容:Early computers are big devices
把这两篇文章中的单词都抽取出来,并且记录下这些单词出现在哪个文档中,这就形成了一个简单粗糙的倒排索引。
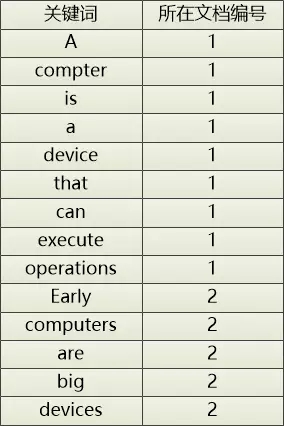
通过这个“倒排索引”,只要给出一个单词,就可以迅速地定位到它在哪个文档中。 用来做全文搜素非常合适。
但是上面的倒排索引有点“粗糙”,还可以在“精化”一下。
1. 对于 a, is , to ,that ,can ,the,are 这些词对搜索来说没什么意义,用户几乎不会用他们搜索,可以过滤掉。
2. 用户搜索的时候虽然输入了computer,但是也希望搜出computers出来,所以需要把复数单词,过去式单词等做还原。
3. 用户虽然输入了device , 但是也希望搜索出Device出来,所以需要把大写都改成小写。
经过这番转换,文档1和文档2的关键字变成了这样:
文档1:[computer] [device] [execute] [operation]
文档2:[early] [computer] [big] [device]
相应地,倒排索引变成了这样:
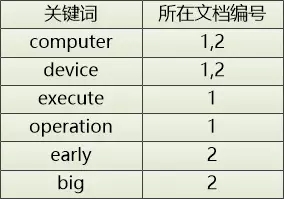
当用户想搜索device 的时候,我们就可以告诉它,在文档1和文档2中都有。
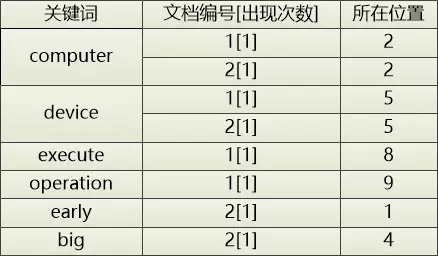
为了更好的统计和高亮显示搜索结果,还可以记录关键词在文章中出现的次数和位置(例如:是第几个单词)
架构
明白了inverted index是怎么回事儿, 张大胖觉得只要把那些书籍的标题,介绍,作者等信息给提取出来,形成inverted index,不就可以做关键字检索了吗?
可是转眼一想,这个需求应该是个通用的需求,不仅是图书馆有,很多互联网应用,例如网上商城也需要, 我完全可以设计一个类库出来,让大家去使用啊。
张大胖迅速画出一个架构图出来:
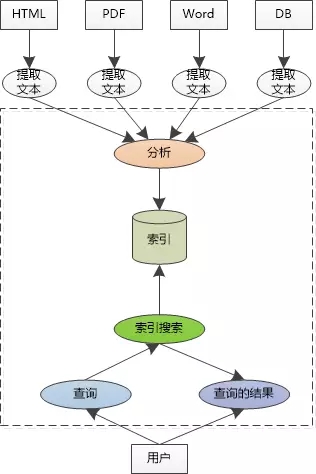
看看,不管你是什么类型的文档,HTML, PDF, Word,甚至是数据库的数据,只要能从中抽取出文本,就可以当作我的数据源,对文本做了分析以后,就可以存入索引库。
用户可以发出各种查询,不仅仅是单个关键字,还支持关键字的组合: keyword1 AND keyword2等,对索引库进行搜索以后,把结果返回给用户。
“中间用虚线框起来的部分就是我应该实现的类库!” 张大胖对这个架构很满意。
抽象
接下来就要考虑这个类库对外提供的API了,这是个很烦人的事情。 张大胖的脑海中不由地想起来好基友Bill的谆谆教导:“软件设计就是一个不断抽象的过程。”, 关键是要抽象啊!
可是这个系统似乎有点复杂,张大胖绞尽脑汁想了两天也没有头绪,对于一个刚学会Web开发的同学,立刻就要设计类库,确实是有点勉为其难。
没办法,张大胖只好致电Bill前来帮忙。
#p#分页标题#e#Bill对张大胖的痛苦表示了亲切的慰问, 又对架构图表示了适度的赞赏。 他说: “既然有HTML,PDF, Word文档, 很自然,你可以做一个Document的抽象!”
“好像不行吧? 如果数据源是数据库,怎么变成Document? ”
“很简单, 比如一行数据就可以映射到一个Document。 当然,这个转化必须得有程序员来完成。程序员决定什么东西是Document。” Bill说。
“Document中有什么东西? ”
“嗯,Document可以有很多属性,每个属性都有名称和值, 我可以把属性叫做Field。比如一个HTML文档,可能有path, title,content等多个Field,其中path可以唯一地标志这个文档, title和content需要做进行分词,形成倒排索引,让用户搜索。” Bill回答。

(一个包含多个Field的Document)
“用户创建了Document和Field以后,就可以进行分析了原始的内容划分成一个个Term,” 张大胖开始开窍,“这样,我可以定义一个Analyzer的抽象类,让别的程序可以扩展它。”
“对,分析的结果可以加入索引库,这个操作可以让一个单独的类,比如IndexWriter类来完成。” Bill 说。
“可是IndexWriter如何知道索引应该存在什么地方? 内存? 文件系统?”
“那就再来一个抽象的概念:Directory,表示索引文件的存储。”
张大胖怕忘记,赶紧画类图:
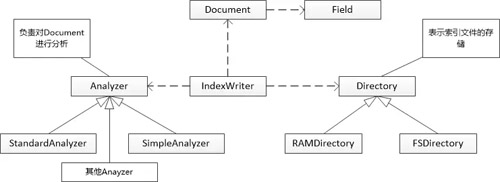
“看起来还是挺漂亮的嘛!” 张大胖说。
“好的设计一般都比较漂亮。” Bill 来了一句至理名言。
“对于对于用户搜索来说,肯定得有个叫做Query的东西,用来表达用户的搜索要求。当然,这个Query也应该允许扩展。 ” 张大胖尝试着抽象。
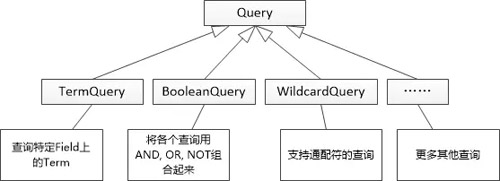
“但是这些类使用起来还是比较麻烦, 最好是支持用户输入字符串来表达搜索的意图:(computer or phone) and price” Bill还是经验老道,“必须得有个解析器来完成从字符串到Query的转化,然后我们让IndexSearcher 来接收Query,就可以实现搜索的功能了。 ”

张大胖很兴奋,一个复杂的系统,就这么被搞定了,虽然其中有很多细节没有覆盖,但大的方向已经确定, 细节在具体的开发中来处理吧。
他摩拳擦掌,准备大干一场,把这个设计给实现了。
可是Bill在网上搜索了一会儿,泼了一盆冷水:“大胖,好像有个叫做Lucene的开源系统,和我们的设计很像啊,功能更加强大,要不你就用它这个实现吧。”
张大胖赶紧跑到电脑前去看,果然,这个叫Lucene的家伙实现得非常完善,还有很多高级的功能,比如仅仅是“相似度”这个功能,非得对搜索有深入研究才行,自己是望尘莫及。
他叹了一口气说:“好吧,我去图书馆找王老师,就用这个Lucene吧!”
三年以后
张大胖已经变成了利用Lucene做搜索的高手,各种细节和最佳实践尽在掌握。随着互联网应用的爆炸式增长,搜索变成了一个常见的需求,他甚至在业余时间专门去给人做Lucene的咨询,赚了不少外快。
但是做得多了,张大胖也觉得很烦,这个Lucene用起来实在是太“低级”,很多人向他抱怨: 我就想搜索一下我的商品描述,现在还得理解什么“Directory”,"Analyzer","Query",实在是太复杂了! 还有我们的数据越来越多,索引也越来占的空间也越来越大,怎么才能实现分布式的存储啊?
这样的抱怨听多了,张大胖心想:是时候对Lucene做一层封装,提供一个简单的API了......
后记:接下来还可以讲一下Elastic Search ,也不知道大家是否感兴趣,再加上这篇文章已经很长了,就停笔了。 如果各位感兴趣的,留言告诉我一下,我会继续写下去。

【本文为51CTO专栏作者“刘欣”的原创稿件,转载请通过作者微信公众号coderising获取授权】